Сравниваем танки
21,449,441
47,380

|
slavae ( Слушатель ) |
| 01 апр 2019 10:26:51 |
Нейросеть распознаёт танки
новая дискуссия Дискуссия 712Здесь
Распознавание танков в видеопотоке методами машинного обучения (+2 видео на платформах Эльбрус и Байкал)
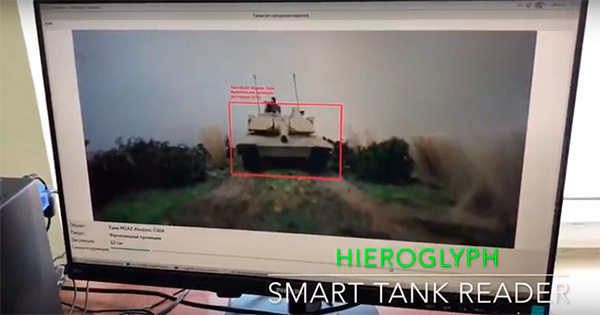
В процессе своей деятельности мы ежедневно сталкиваемся с проблемой определения приоритетов развития. Учитывая высокую динамику развития IT индустрии, постоянно возрастающую востребованность со стороны бизнеса и государства к новым технологиям, каждый раз, определяя вектор развития и инвестируя собственные силы и средства в научный потенциал нашей компании, мы следим за тем, чтобы все наши исследования и проекты носили фундаментальный и междисциплинарный характер.
Поэтому, развивая нашу главную технологию – фреймворк распознавания данных HIEROGLYPH, мы заботимся как о повышении качества распознавания документов (наша основная бизнес-линия), так и возможности применения технологии для решения смежных задач распознавания. В сегодняшней статье мы расскажем, как на базе нашего движка распознавания (документов), мы сделали распознавание более крупных, стратегически важных объектов в видеопотоке.
Постановка задачи
Используя имеющиеся наработки построить систему распознавания танков, позволяющую проводить классификацию объекта, а также определять базовые геометрические показатели (ориентацию и расстояние) в слабоконтролируемых условиях без использования специализированного оборудования.
Решение
В качестве основного алгоритма при решении задачи мы выбрали подход статистического машинного обучения. Но одной из ключевых проблем машинного обучения, является необходимость наличия достаточного количества обучаемых данных. Очевидно, что натуральные изображения, полученные с реальных сцен, содержащие необходимые нам объекты, нам недоступны. Поэтому было решено прибегнуть к генерации необходимых данных для обучения, благо опыт в этом месте у нас большой (https://habr.com/ru/company/smartengines/blog/264677/). И все же, полностью синтезировать данные для данной задачи нам показалось неестественным, поэтому для моделирования реальных сцен был подготовлен специальный макет. На макете установлены различные объекты, моделирующие сельскую местность: характерное ландшафтное покрытие, кусты, деревья, заграждения и т.д. Изображения захватывались с помощью цифровой малоформатной камеры. В процессе захвата изображений существенно менялся задний план сцены для обеспечения большей устойчивости алгоритмов к изменениям фона.

В качестве целевых объектов выступали 4 модели боевых танков: Т-90 (Россия), М1А2 Абрамс (США), Т-14 (Россия), Меркава III (Израиль). Объекты располагались на различных позициях полигона, тем самым расширяя список допустимых видимых ракурсов объекта. Значительную роль сыграли инженерные заграждения, деревья, кусты и прочие ландшафтные элементы.

Таким образом, за пару дней мы собрали достаточный набор для обучения и последующей оценки качества работы алгоритма (несколько десятков тысяч изображений).
Непосредственно распознавание решили разбить на две части: локализация объекта и классификация объекта. Локализация выполнялась с помощью обученного классификатора Виолы и Джонса (все-таки танк — это нормальный ригидный объект, ничем не хуже чем лицо, поэтому “слеповатый на детали” метод Виолы и Джонса быстро локализует целевой объект). А вот классификацию и определение ракурса мы доверили сверточной нейронной сети — в этой задаче нам важно, чтобы детектор успешно выделял те особенности, которые, скажем отличают Т-90 от Меркавы. В результате удалось построить эффективную композицию алгоритмов, успешно решающую задачу локализации и классификации однотипных объектов.

Далее, мы запустили полученную программу на всех имеющихся у нас платформах (Intel, ARM, Эльбрус, Байкал, КОМДИВ), оптимизировали вычислительно-трудные алгоритмы для повышения быстродействия (про это мы уже неоднократно писали в своих статьях, например тут https://habr.com/ru/company/smartengines/blog/438948/ или https://habr.com/ru/company/smartengines/blog/351134/) и добились устойчивой работы программы на устройстве в режиме реального времени.
В результате проведения всех описанных действий у нас получился полноценный программный продукт, обладающий существенными тактико-техническими характеристиками.
Smart Tank Reader
Итак, представляем вам нашу новую разработку — программу для распознавания образов танков в видеопотоке Smart Tank Reader, которая:

- Решает задачу “свой-чужой” для заданного набора объектов в режиме реального времени;
- Определяет геометрические показатели (расстояние до объекта, преимущественная ориентация объекта);
- Работает в неконтролируемых погодных условиях, а также в случае частичного перекрытия объекта посторонними объектами;
- Полностью автономная работа на целевом устройстве, в том числе в условиях отсутствия радиосвязи;
- Список поддерживаемых процессорных архитектур: Эльбрус, Байкал, КОМДИВ, а также x86, x86_64, ARM;
- Список поддерживаемых операционных систем: ОС Эльбрус, ОС AstraLinux, ОС Атликс, а также MS Windows, macOS, различные дистрибутивы Linux, поддерживающие gcc 4.8, Android, iOS;
- Полностью отечественная разработка.
Обычно в заключении к своим статьям на Хабре мы даем ссылку на маркетплейс, где каждый желающий с помощью своего мобильного телефона может скачать демонстрационную версию приложения, чтобы на деле оценить работоспособность технологии. В этот раз, учитывая специфику получившегося приложения, мы желаем всем нашим читателям никогда не в жизни сталкиваться проблемой оперативного определения принадлежности танка к определенной стороне.
ОТВЕТЫ (18)
|
|
Alexandr Ivanov Nette ( Слушатель ) |
| 01 апр 2019 10:40:32 |
Цитата: slavae от 01.04.2019 10:26:51
все это давно известно.
тут важны ровно 5 вопросов:
1. время распознавания (заявляется РВ, хотелось бы в цифрах- секунда две, три...))
2.ошибка распознавания (танк/не танк)
3.ошибка идентификации (т90, м1 и т.п.)
4.вычислительные мощности
5.дистанция распознавания
и я б добавил 6 вопрос-распознавание не только в видимом диапазоне, но и по ИК сигнатуре.(причем для ЭОП и для тепловизора и какая минимальная матрица необходима в тепловизоре )
|
|
Head790 ( Слушатель ) |
| 01 апр 2019 12:15:36 |
Для лабораторного прототипа много вопросов:)
Система распознавания лиц сложнее, но у китайцев, например, работает результативно.
Для распознавания среди десятка объектов много мощностей не нужно. В габариты системного блока впишется(может и меньшие)
Распознавание в ИК, других диапазонах или комбинированном виде вряд ли сильно сложнее, принципиальной разницы для этих систем нет, что анализировать.

|
Luddit ( Слушатель ) |
| 01 апр 2019 12:30:49 |
Цитата: Head790 от 01.04.2019 12:15:36
ИМХО, их обучать сложней - ибо человек сам не очень представляет, как оно там выглядит. В оптическом же диапазоне плюс к тому человек планку задает - типа в данной ситуации распознать можно.

|
rommel.lst ( Практикант ) |
| 01 апр 2019 12:46:40 |
Цитата: Luddit от 01.04.2019 12:30:49
Обучать распознавалку рож вообще просто - ставите кучу сильно разных фоток одной и той же хари, добиваетесь, чтоб НС стала "понимать", что это оно самое, ну и все, готов качественный коррелятор. Обычно в качестве входных параметров пихают пару дюжин ключевых зон, этого за глаза хватает..
|
|
Alexandr Ivanov Nette ( Слушатель ) |
| 01 апр 2019 21:32:50 |
это если распознать одного из 100.
а если 1 из 146 млн (РФ) или 7,5 млрд (весь мир)-тут сильно сложнее.
думается , что с танками сделать программу для распознавания будет и легче (типов танков сильно меньше, чем типов лиц человеческих) и сложнее (шмурдяк, непредсказуемо закрывающий "ключевые зоны" для распознавания, да и просто-банальный камуфляж, опять же распознавание по ик-сигнатуре)
|
|
Alexandr Ivanov Nette ( Слушатель ) |
| 01 апр 2019 21:12:09 |
Цитата: Head790 от 01.04.2019 12:15:36
лабораторные прототипы были забацаны еще в 80-е и работали на см4 (не по танкам, правда, но это не принципиально)
Цитата: Head790 от 01.04.2019 12:15:36
в стационарном варианте
Цитата: Head790 от 01.04.2019 12:15:36
4 gf1080 или че там сейчас поновее плюс cuda, ну, наверное, да, задачу в РВ должны потянуть.Вопрос в оптимизации кода...
Цитата: Head790 от 01.04.2019 12:15:36
дьявол кроется в деталях.
для эопа-вопрос в требуемой алгоритмом распознавания детализации картинки и, следовательно, разрешающей способности от эопа
для тепловизора-кмк,еще сложнее.
1. необходимое количество пикселей для уверенного распознавания-это к матрице тепловизора
2. ик сигнатура танка работающего и простоявшего , скажем , пару тройку часов-разная. также сигнатура изменяется от погоды-день, ночь, подстилающая поверхность-все это дает достаточно сильно разную картинку для распознавания. алгоритмы это учитывают?
в общем, тема конечно интересная и, скорее всего, перспективная, но, по выражению Грефы-"тупицца тим"-команда из 10-15 чел, не смотря на уже имеющиеся сертификаты, эту тему, кмк, не потянет, а, значит, нужно бабло в размерах и время...-и не факт, что через пару-тройку лет окажется, что алгоритмы были выбраны не совсем верно, раздутый код -еле шевелится, а главный менеджер проекта краснея и заикаясь, не будет отвечать перед СК ( см. дело Т-платформ). А потом, на всю оставшуюся жизнь, зарекется работать с государством-вообще и МО-в частности.
|
|
Миша_0f3d74 ( Слушатель ) |
| 07 апр 2019 07:47:05 |
Цитата: Head790 от 01.04.2019 12:15:36
Быстродействие при сопоставлении объектов напрямую зависит от базы данных объектов и элементов, а также от времени экспонирования сцены и изменения ракурса.
Так как в той математике, что написали когда-то в ИСС и ИТВ, для распознавания лиц и объектов, анализировались отдельные кадры, а изменение сцены, за счет анализа дельта-преобразования.
Кстати, китайцы пользуются разработанными нашими математиками алгоритмами. Легально ли - не знаю.
Штатники их вполне официально купили году в 2005-6.
В общем, для анализа сцен с 16 камер разрешения 720*576*12 кадров, хватало компа на пне-4 сокет 423, с гигом оперативки рамбус и обычными сказевыми винтами ибм.
Причем конфигурация выглядела явно избыточной, потому что потом к ней прикрутили еще и писалку для телефонов на 16 номеров. И ничего не затормозило.
Практически все камеры, начиная с достаточно древних, неплохо видят в ближнем ИК. Некоторые, за счет разработанной опять же нашими специалистами, технологии, при которой, при ухудшении освещенности, контроллер матрицы постепенно отключает цветность, а потом уменьшает разрешение, за счет чего увеличивается размер ячейки и кратно повышается чувствительность. И это даже без подсветки.
Через тепловизор с той же ЭОП, матрица будет видеть не хуже.
Еще в середине-конце 2000-х, на границе на Кавказе, были установлены убер-пупер системы контроля, включая радиолокационные датчики.
Вот они в систему интегрировались как-то иначе, чем просто как картинка. У них есть свои базы данных сигнатур объектов и это полностью отдельный канал распознавания.
|
|
Alexandr Ivanov Nette ( Слушатель ) |
| 08 апр 2019 12:18:35 |
кхмы.
Вы немного путаете.
ЭОП-электронно-оптический преобразователь-работает в ближнем инфракрасном, в ближнем ультрафиолетовом и в видимом диапазоне ЭМВ на принципе усиления входного сигнала и сужения спектра выходного сигнала до монохромного . Результат-в полной темноте в ПНВ (прибор ночного видения) с ЭОПом ничего не видно.
Тепловизор работает в другом диапазоне-среднем ИК-и по другому принципу-сканирует разность теплового излучения соседних участков в поле зрения прибора. Результат -может работать в полной темноте, главное, что бы в поле зрения был градиент температур (объекты отличались друг от друга температурой). С другой стороны, если температура объектов в поле зрения не отличаются друг от друга и от подстилающей поверхности -то тепловизор ничего не зарегистрирует ("не увидит").
Отсюда сложность в распознавании при использовании двух каналов- логически связать два объекта , которые выглядят в видимом диапазоне и в инфракрасном спектре по разному (разный силуэт, яркостные пятна в разных местах на силуэте и т.п.))
|
|
Cannon75 ( Слушатель ) |
| 01 апр 2019 12:37:38 |
Важнее другое. Сколько пикселей должно быть в картинке, чтобы алгоритм работал? А то разглядеть и распознать объект. который занимает 10-ую часть картинки - это одно... а вот на панорамном снимке опознать объект высотой в 7 пикселей только человек может.
На шасси человека смонтирована весьма совершенная оптическая система. Как результат - человек способен опознать танк на дистанции километра 2-3 вполне уверенно. То же самое для машинной обработки возможно только при наличии весьма крутой оптики на стабилизированной платформе.
|
|
pkb ( Слушатель ) |
| 01 апр 2019 14:10:11 |
Цитата: Cannon75 от 01.04.2019 12:37:38
У меня постоянно возникал вопрос распознавания, когда читал описания Джевелин с его 64 на 64 пикселя или ПЗРК - там вообще типа 1 пикселя - мол почему так примитивно? что их можно обмануть тепловыми ловушками - человеческий глаз же не обманешь. Берешь камеру от телефона, компьютер - т.е. берешь смартфон и вуаля, "ГСН готова".
Но кроме ночного режима всплывают проблемы:
фокусировка - та же Сирия, когда бабахи снимают на телефон постоянно фокус уходит, и тогда самолет невиден на фоне неба.
И ещё что-то, поэтому и пользуют 64 пикселя или как в ПЗРК.
|
|
Alexandr Ivanov Nette ( Слушатель ) |
| 01 апр 2019 21:25:00 |
Цитата: Cannon75 от 01.04.2019 12:37:38
ну, примерно про то я и намекнул, прочитав текст и заглянув по ссылке на хабр.
в общем, я бы, для получения достоверного демообразца посадил бы работать параллельно пару-тройку команд по алгоритмам и 3-4 команды кодеров.
ну, а потом можно перейти к разработке программно-аппаратного комплекса (оптика, ик аппаратура, гиростабилизированная платформа, вычислительный блок на специализированных микросхемах) для получения опытного образца...
ну и совсем потом-испытания, доработка и т.д....-все это легко потянет лет на 10 (в прямом и переносном смысле).
|
|
Миша_0f3d74 ( Слушатель ) |
| 07 апр 2019 07:51:54 |
Цитата: Cannon75 от 01.04.2019 12:37:38
При человеческую систему зрения можно только восхищаться, согласен. Она и динамическая и адаптивная и с огромной базой данных образов, которая правда иногда косячит, выдавая неправильное решение.
Но вот чтобы человек, не вооруженный весьма крутой оптикой, опознал танк на дистанции в 2-3 километра?!
Да этот танк должен бегать, прыгать и хоботом размахивать!
Просто стоящий танк опознать на расстоянии в 2 км, вооружившись полевым восьмикратником, емнип, человеков специально учат в военных училищах.
|
|
Danila ( Слушатель ) |
| 07 апр 2019 10:30:07 |
Если у человека нет проблем со зрением и хорошая видимость, разглядеть не укрытый-спрятанный танк с двух километров невооружённым глазом, равно как и другой крупный объект, не составляет проблемы. Это я вам как человек с нормальным зрением говорю.

|
part_ya ( Практикант ) |
| 01 апр 2019 16:39:27 |
Требую умения отличать друг от друга в дыму с километра Т-34 сборки разных заводов и лет выпуска, а чешский Т-34-85 отличать от тагильского с 2х в сумерках!


|
Neruda ( Слушатель ) |
| 03 апр 2019 07:10:34 |
Я не спец по нейронкам, но маленько ковырялся в них, так могу немного ответить по теме, но чисто теоретически.
0. Основная проблема нейронок, это правильное моделирование сети и ее обучение. Это как с ребенком, если генетика хорошая и учителя вменяемые то результат будет приемлемым. Вообще тема нейронок в задаче распознавания настолько разобрана и разжевана, что это даже не задача, а лабораторный практикум для студентов после прохождении темы "Закон Ома". То есть програмист нам не нужен, нам нужен воспитатель.
1. Скорость распознавание достаточно велика, но зависит от размера и модели сети. Математика там простая, перемножение матриц, как ячейки в екселе, много ячеек. Но ничего сверхестественного, никаких тройных интегралов, по замкнутому контуру.
2. Принято формальное правило, 98% - хороший результат, 99- отличный, 100 - нереальный. 146%- ошибка в обучении.
3. Идентификация - это следующий уровень обучения. Сперва учить опознавать нейронку, что это танк, а потом, эту обученную, учим опознавать модели. Даже человека нельзя научить сразу метко и быстро стрелять. Сперва либо быстро, либо метко, а потом либо метко, либо быстро. Но если сильно хочется, то можно.
4, Большие мощности нужны для процесса обучения, чем круче тем быстрее обучить. А для работы хватит трофейного Пенька-2 на 120 мегагерц, особенно если код будет написан на низком уровне, а не на питоне как щас принято.
5, Дистанция не имеет значения. Значение имеет размер картинки, которую необходимо "осмотреть". То есть, какая у вас будет оптика и матрица в фотике, такая будет и дистанция. Если прикрутить эту нейронку к Хаблу, то он прекрасно может "запалить" БлекШакрка и на Альфе Центавре, но с условием, что он будет в танке.
6. Пох, видимый, не видимый. Какие картинки вы будите показывать в процессе обучения, такие нейронка научится распознавать. Есть метода, многослойное распознавание, по каналам, типа R-G-B. Так что, как в анекдоте "Доктор, откуда вы берете такие картинки?"
По поводу размера исходного изображения, тут был такое вопрос.
Отвечаю, размер не имеет значения. Хотя, чем больше тем лучше, но дольше.
Как это делается:
Если картинка как у Джавелина 64х64 пикселя. Это 64х64=4096 пикселей во всей картинке. Это уже много, но пусть будет так.
Каждый пиксель это информация о цвете это пикселя, если изображение цветное, то число от 0 до 65535, или от 0 или 1, если черно-белое. Нейронке по сути, без разницы ч/б или цветное. Количество цветов влияет на вычислительные мощности, чем меньше цветов тем быстрее будет считать. Но для упрощения процесса, все картинки переводят в ч\б или градации серого.
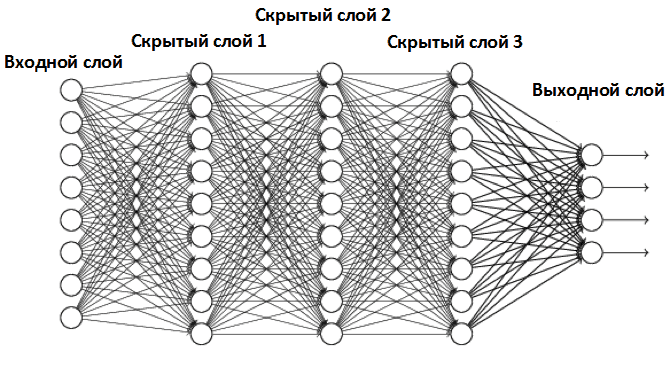
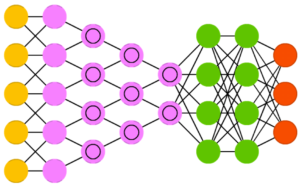
Итак имеем 4096 входных данных, это первый слой нейронки. Каждый пиксель отдается одному нейрону, то есть имеем 4096 нейронов в первом слое. Далее идет 2-й,3-1 n-й слои, так называемые скрытые слои. И на выходе - выходной слой.
Если вы рыбак, то представьте себе полотно рыболовной сети.
Узелки это нейроны, леска от узелков это связи нейронов между собой, причем каждый узелок связан со всеми соседями, слева и справа.. Первый столбец узелков слева- это входной слой, последний столбец с права это выходной, а между ними скрытые слои, там творится "магия". Скрытых слоем может быть от 1-го до бесконечности, в зависимости от модели сети.
В задачах классификации, модель сети выглядит как треугольник, первый слой равен количеству входных данных.
В нашем случае 4096/
Выходной равен 2, в нашем случае, танк или не танк.
Или даже выходной равен 1, насколько это танк в %
Теперь имеем сеть, мы должны ее обучить. Для этого на понадобится туева-куча картинок с танками или без, размером 64х64,
Делим эту кучу на две неравные части, большая это для обучения, меньшая для проверки результатов этого обучения.
По очереди, из обучающей кучи, "показываем" картинку сети, то есть в входной слой запихиваем 4096 значений из пикселей картинки.
И смотрим, что получили на выходном слое.
Если сеть не угадала, то производим "обучение". то есть меняем коэффициенты весов в скрытых слоях.
Что такое "обучение", писать не буду, там мат.ан и прочие фокусы.
Но все это уже есть в открытом доступе, и любой школьник следуя инструкциям может забабахать себе нейронку для любых целей, хоть для полета на луну.
В итоге, после недели, месяца или года, получаем обученную сеть.
Если все аккуратно делать, то будет уверено распознавать танки на любых изображениях размерностью 64х64.
А вот что делать если картинка у нас размером не 64х64, а больше.
Все уже
Это называется сверточные нейронные сети. Физически их работа выглядит так:
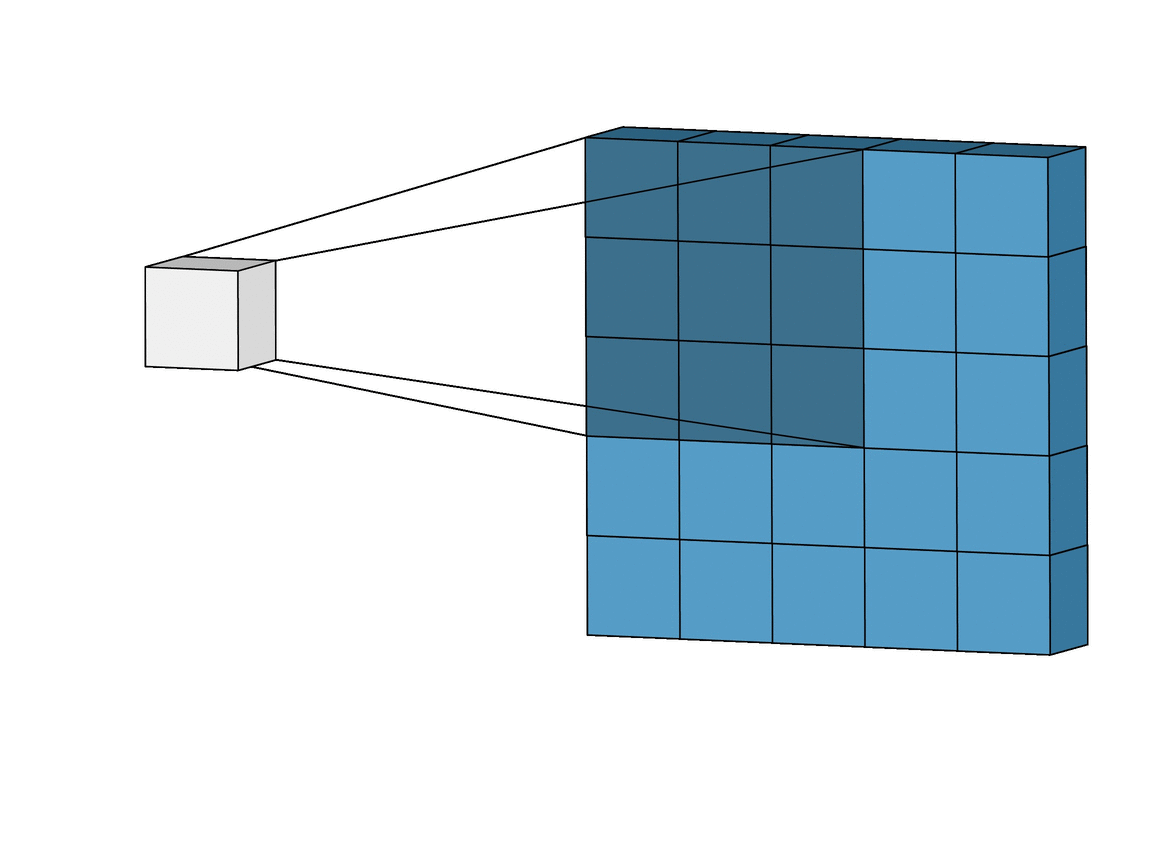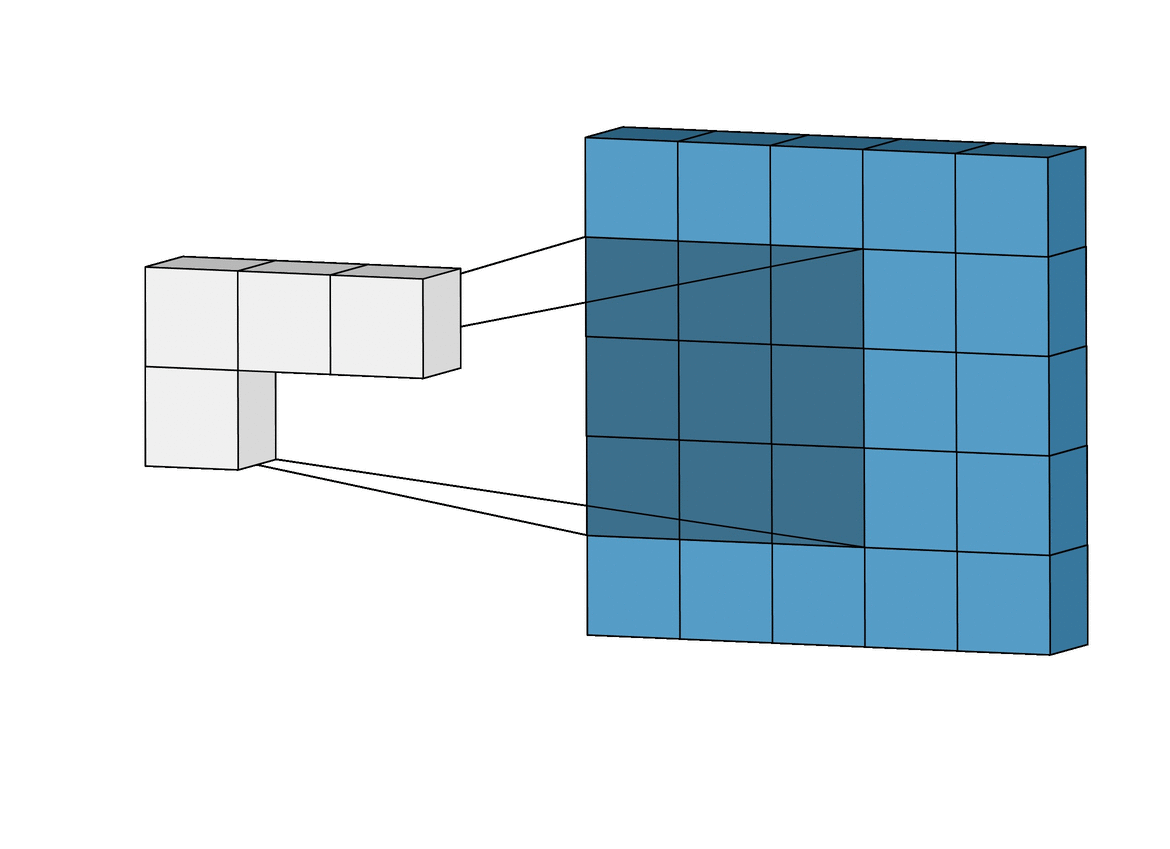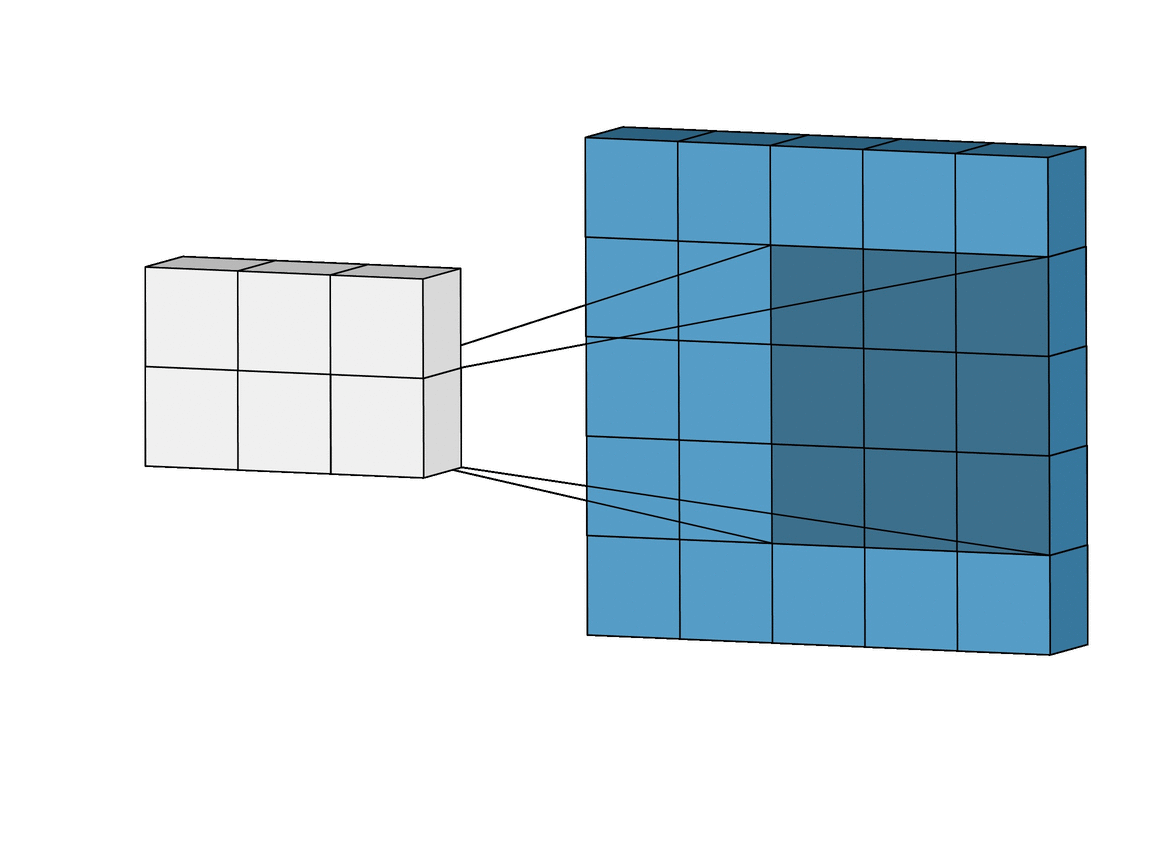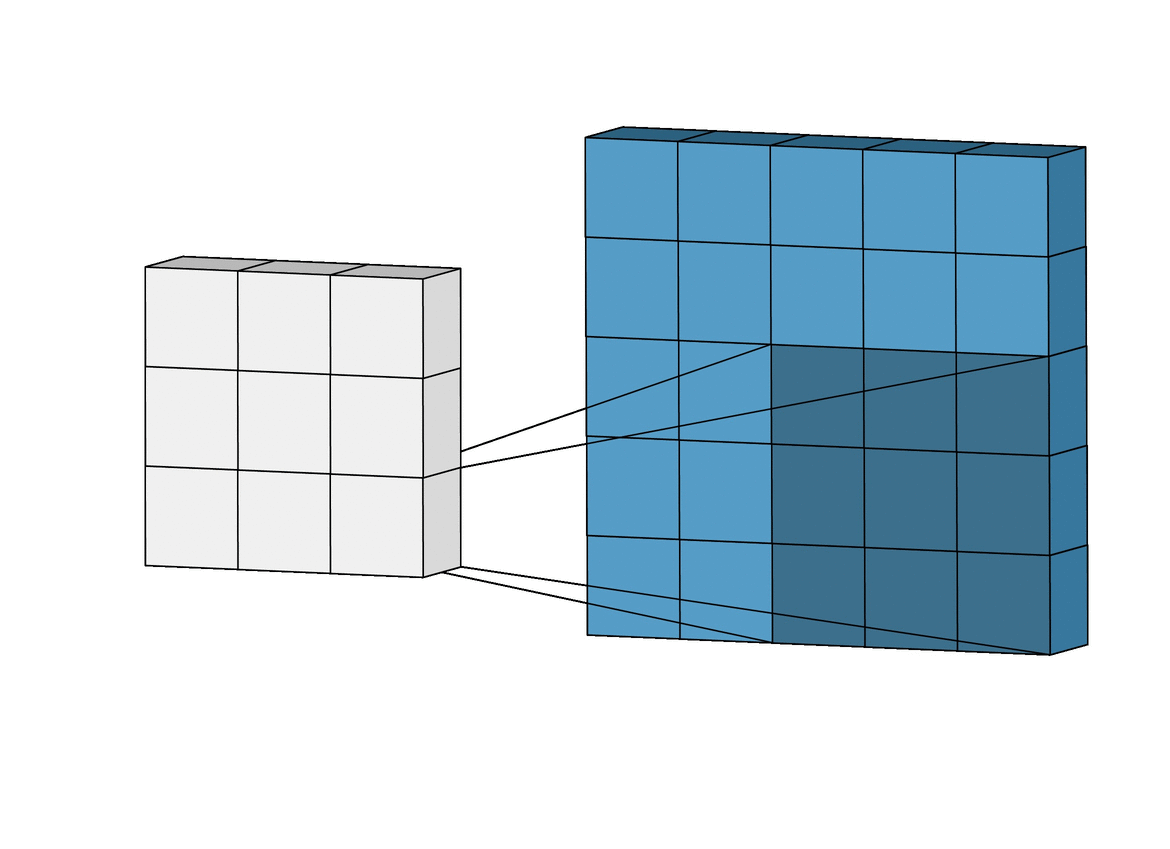
Свёрточные нейронные сети (convolutional neural networks, CNN) и глубинные свёрточные нейронные сети (deep convolutional neural networks, DCNN) сильно отличаются от других видов сетей. Обычно они используются для обработки изображений, реже для аудио. Типичным способом применения CNN является классификация изображений: если на изображении есть кошка, сеть выдаст «кошка», если есть собака — «собака». Такие сети обычно используют «сканер», не парсящий все данные за один раз. Например, если у вас есть изображение 200×200, вы не будете сразу обрабатывать все 40 тысяч пикселей. Вместо это сеть считает квадрат размера 20 x 20 (обычно из левого верхнего угла), затем сдвинется на 1 пиксель и считает новый квадрат, и т.д. Эти входные данные затем передаются через свёрточные слои, в которых не все узлы соединены между собой. Эти слои имеют свойство сжиматься с глубиной, причём часто используются степени двойки: 32, 16, 8, 4, 2, 1. На практике к концу CNN прикрепляют FFNN для дальнейшей обработки данных. Такие сети называются глубинными (DCNN).
Читать статью (стр. 2278—2324)
То есть, сеть не смотрит все изображение сразу, а постепенно, пробегая по нему неким "окном" обычно 20х20 пикселей. В итоге выдавая результат.
Причем в военное время размер окна может достигать 4-х пикселей. как на "Игле" если я не ошибаюсь
После обучения, сеть нужно внедрить в боевого робота. Это не сложно, и не очень большой объем данных.
1. Это программный код, реализующий модель нейронной сети. Порядка 5-6 экранов исходного текста на С/С#.
2. Массив коэффициентов весов, те который мы так долго и нудно "тренировали". Их размер зависит от модели, примерно от нескольких килобайт, до мегабайт.
Ничего сверх-естественного, справится практически любой процессор, даже Z80, еще и свободного времени останется, на осознание смысла жизни.

Что я хотел всем этим сказать? По сути новость, это из разряда, даже не диплома, а реферата, студента 4-го курса.
ЗЫ:
Так как тутта этто оффтопо, то АС, а АУнаУМ.
|
|
Alexandr Ivanov Nette ( Слушатель ) |
| 06 апр 2019 18:24:17 |
Цитата: Neruda от 03.04.2019 07:10:34
0. моделирование-не проблема. проблема -правильное моделирование.
1.математика-простая, если параметры распознавания просты (множество параметра А не пересекается с множеством параметра Б.(например лысый/волосатый)), а мощности-мощны. А, если параметры распознавания сложны-ошибка распознавания начинает сильно повышаться (множество параметра А пересекается со множеством параметра Б (волосы длинные/короткие)).математика будет сложной и при большом количестве параметров распознавания и ограниченных вычислительных возможностях.
2.Зависит от хотелок заказчика и от цены ошибки распознавания.
3.-
4.При обучении-есть такое. При работе-зависит от величины массива входных данных и тонкости распознавания и идентификации. Общее правило-чем лучше сделана программа, тем меньше требования к рабочему железу-в данной ситуации работает на все сто.
5.Дистанция тут важна не "напрямую", а опосредственно. Дистанция вносит дополнительные искажения затрудняющие распознавание и идентификацию и стоимость программно-аппаратного комплекса из-за увеличения требований к оптическому каналу.
6. в общем случае-так. в случае с танками (военной техникой) проблема в непредсказуемо искажающей силуэт маскировке. Даже для человека это огромная проблема, которая, правда, сильно облегчается если объект движется. Для нейросетей движение объекта не облегчает (не сильно облегчает, при наличии СДЦ), а часто и затрудняет обнаружение и идентификацию.