IT в России и мире в реалиях мирового кризиса
1,416,248
8,485
|
|
Slav Rus ( Слушатель ) |
| 07 ноя 2020 12:28:47 |
В России создана оригинальная процессорная архитектура, способная потеснить NVidia
новая дискуссия Дискуссия 371
.
06.11.2020
Как выяснил CNews, в России в I квартале 2021 г. будут выпущены первые образцы отечественных чипов, реализованных на новейшей процессорной архитектуре IVA TPU. Она была разработана российской компанией IVA Technologies, которая входит в группу «Хайтэк».
Перспективность этой архитектуры, ориентированной на нейронные сети, в конце октября 2020 г. была подтверждена в ходе тестирования на площадке MLPerf. Данная организация представляет собой международный консорциум, который был создан в 2018 г. для разработки универсальных тестов, позволяющих измерить эффективность систем искусственного интеллекта. Учредителями MLPerf выступают Baidu, Google, Гарвардский, Стенфордский и Калифорнийский университеты, а также университет в Беркли. В состав аттестующих рабочих групп входят сотрудники ARM, Facebook, Google, Microsoft, HP, IBM, Intel, Nvidia, Cisco, Cray и др.
На тестах архитектура IVA TPU была квалифицирована в том числе (но не только) в самую сложную, по данным разработчика, группу Closed Division Edge — закрытый список сетей с ограничениями на модификации, время ожидания и точность.
«Из анализа результатов видно, что для одной из самых распространенных нейронных сетей (Resnet-50), архитектура IVA TPU обеспечивает задержку в три раза меньше, чем Xilinx Alveo U250. То есть IVA TPU превосходит по ключевому параметру лучшее решение одного из мировых лидеров, спроектированное специально под искусственный интеллект, — пояснили CNews разработчики. — Планируется, что при реализации ускорителя с архитектурой IVA TPU в ASIC (интегральной схеме спецназначения; — прим. CNews) результаты будут лучше, чем у нашего ближайшего конкурента NVidia Jetson Xavier NX — несмотря на отставание в технологии: 28 нм против 12 нм».
«Успешное участие в тестировании на общепринятой методике с жестким аудитом результатов — это в первую очередь показатель зрелости решения, его готовности к промышленному применению», — отметил в разговоре с CNews заместитель гендиректора IVA Technologies, руководитель направления Евгений Терентьев.
....
https://www.cnews.ru…novejshaya
ОТВЕТЫ (15)

|
adolfus ( Слушатель ) |
| 08 ноя 2020 02:13:29 |
Цитата: Slav Rus от 07.11.2020 12:28:47
Nvidia не занимается нейросетями и ничего для их моделирования специально не выпускает. Nvidia занимается высокопроизводительными вычислениями, рендерингом графики и чипсетами для материнок. И причем Nvidia GPU к IVA TPU не совсем понятно. Это как сравнение безногого с хромым – второй в любом случае потеснит первого на соревнованиях по ходьбе.
|
|
dmitriк62 ( Слушатель ) |
| 09 ноя 2020 11:01:27 |
Цитата: adolfus от 08.11.2020 02:13:29
Вы б хоть пару строк прочитали про архитектуру Нвидии, прежде чем писать сюда такую чушь.
Значительная часть кристалла у них — тензорные процессоры, которые и реализованы в обсуждаемом устройстве.
|
|
adolfus ( Слушатель ) |
| 10 ноя 2020 01:03:56 |
Цитата: dmitriк62 от 09.11.2020 11:01:27
У них – это у кого? У нвидии? Модель GPU назовите, у которой значительная часть кристалла "тензорные" процессоры. Я больше имею дело с вычислениями на их гпу через куду и другими их железками не интересуюсь.
И, кстати, что это за процессоры такие, "тензорные"? Стово "тензорный" в приложении к нейросетям означает обыкновенную двумерную свертку, возраст которой в быстром варианте семьдесят с лишним лет (ЕМНИП, в 1946 году опубликовали первую статью про двумерное БПФ, лежащее в ее основе).
|
|
dmitriк62 ( Слушатель ) |
| 10 ноя 2020 10:40:12 |
Цитата: adolfus от 10.11.2020 01:03:56
Ну вот современный кристалл GA100:
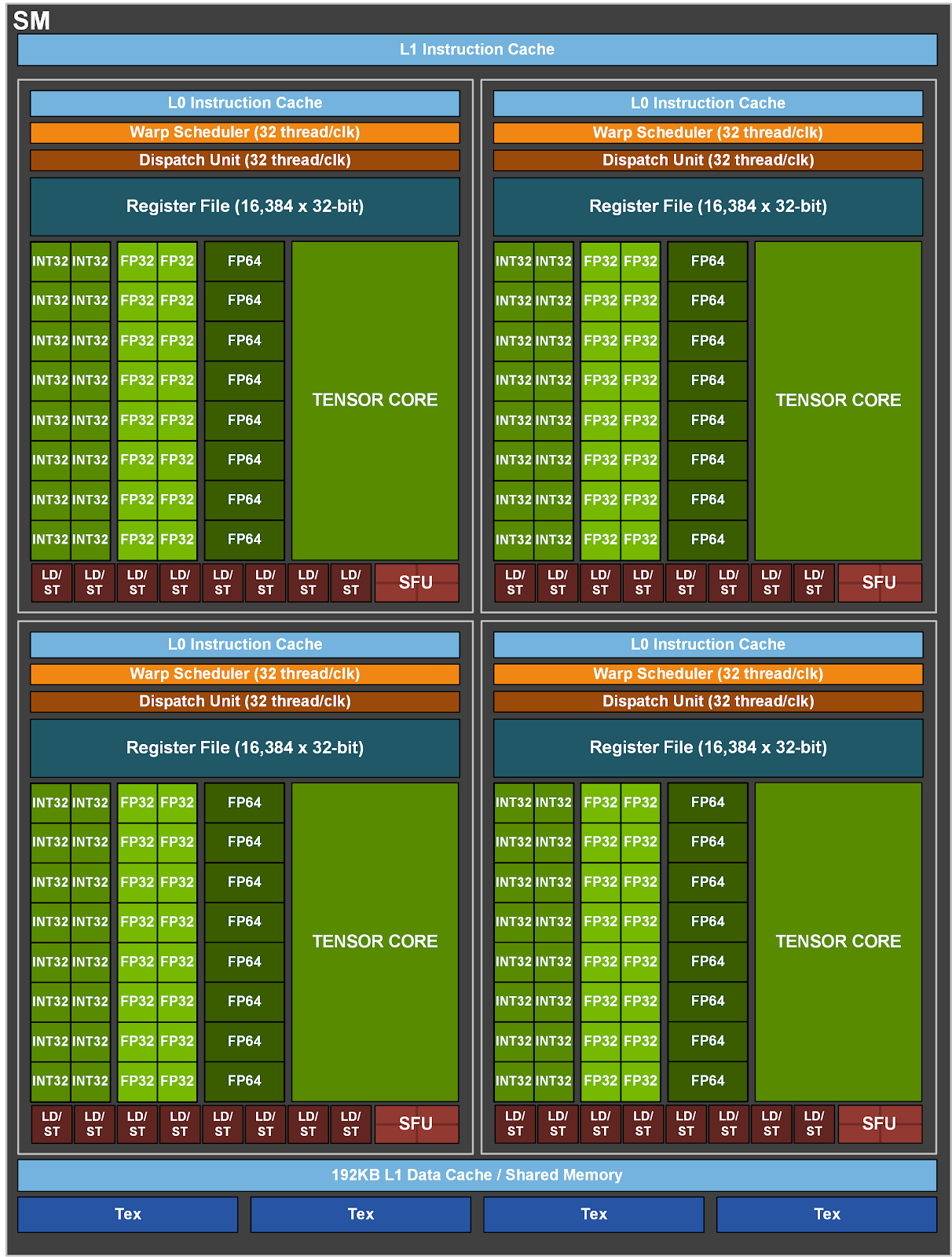
Есть огромная масса приложений, которая использует только эту часть, CUDA там нужна только для загрузки тензорных регистров.
Остальное на чипе у Ненавидии просто простаивает на этих задачах.
И вот наши ребята для таких модных приложений сделали вдвое более эффективную архитектуру без всех остальной требухи вроде видеодекодера, текстуринга, трассировки лучей, всяких int/float/double вычислителей и т.д.
Так что им можно только рукоплескать...
|
|
adolfus ( Слушатель ) |
| 10 ноя 2020 12:06:43 |
Цитата: dmitriк62 от 10.11.2020 10:40:12
Эти "тензорные" ядра никакого отношения к AI не имеют – это просто ускорители операции свертки c^i_j = a^i_k b^k_j. То, что их используют в
|
|
dmitriк62 ( Слушатель ) |
| 10 ноя 2020 12:40:03 |
Цитата: adolfus от 10.11.2020 12:06:43
Вы пишете о вещах, о которых не имеете ни малейшего представления.

|
|
adolfus ( Слушатель ) |
| 10 ноя 2020 20:23:27 |
Цитата: dmitriк62 от 10.11.2020 12:40:03
Не надо столь аппеляционно... Вот читата из документации на кишки того самого GA100, что Вы упомянули (стр. 22)
ЦитатаThird-Generation NVIDIA Tensor Core
Tensor Cores are specialized high-performance compute cores for matrix math operations that
provide groundbreaking performance for AI and HPC applications. Tensor Cores perform matrix
multiply and accumulate (MMA) calculations...
-- Пщщпду екфтыдфеу --
Тензорные ядра – это специализированные высокопроизводительные вычислительные ядра для матричных математических операций, которые обеспечивают революционную производительность для приложений AI и HPC. Тензорные ядра выполняют вычисления матричного умножения с накоплением (MMA)...
Этот самый "matrix multiply" и есть свертка в ее чистейшем виде. Запишу еще раз эту операцию лично для Вас в тензорной нотации:
c^i_j = a^i_k b^k_j
На всякий случай, если Вы "не имеете ни малейшего представления" о LaTeX, картинку даю
На всякий случай, если Вы "не имеете ни малейшего представления" о тензорной нотации, даю картинку в матричной форме в компонентах
Там, правда, про MMA, но даже коза знает, что MMA = MM + A. (в чисто матричной форме)
На следующей странице того же мануала вышеизложенное развивается и детализируется для школоло
ЦитатаGeneral Matrix-Matrix Multiplication (GEMM) operations are at the core of neural network
training and inference, and are used to multiply large matrices of input data and weights in
various layers. The GEMM operation computes the matrix product D = A * B + C, where C and
D are m-by-n matrices, A is an m-by-k matrix, and B is a k-by-n matrix. The problem size of
such GEMM operations running on Tensor Cores is defined by the matrix sizes, and typically
denoted as m-by-n-by-k.
даже переводить не буду...
|
|
dmitriк62 ( Слушатель ) |
| 11 ноя 2020 09:55:26 |
Цитата: adolfus от 10.11.2020 20:23:27
Послушайте, господин любитель оскорбить.
Я Вам не школоло.
А вот Вы, копирующий детсадовскую элементарщину из учебника (видимо, и сам не особо её понимая) — типичный трололо.
Вы хоть посмотрели бы, с какими типами данных работает вся эта сноповязалка, тогда, может быть, и задумались бы, для чего всё это сделано...

|
|
Вариант ( Слушатель ) |
| 11 ноя 2020 11:05:28 |
Об NVDIA
Господа-товарищи-коллеги , а не проще было у nvidia спросить, делается там что-то или нет в обсуждаемом вами направлении. Извините, просто удивило, что никто не сходил к ним на сайт ну или не дал ссылок.
https://www.nvidia.c…xavier-nx/
https://www.nvidia.c…/learn-ai/
https://www.nvidia.c…-platform/
Господа-товарищи-коллеги , а не проще было у nvidia спросить, делается там что-то или нет в обсуждаемом вами направлении. Извините, просто удивило, что никто не сходил к ним на сайт ну или не дал ссылок.
https://www.nvidia.c…xavier-nx/
https://www.nvidia.c…/learn-ai/
https://www.nvidia.c…-platform/
|
|
adolfus ( Слушатель ) |
| 11 ноя 2020 20:20:36 |
Цитата: Вариант от 11.11.2020 11:05:28
Я выше дал ссылку на документацию, где черным по белому написано, что эти "тензорные" процессоры вычисляют свертку с накоплением.
|
|
dmitriк62 ( Слушатель ) |
| 12 ноя 2020 11:00:32 |
Цитата: adolfus от 11.11.2020 20:20:36
В отличие от Вас, я эту документацию давно зачитал до дыр.
Нвидия (в отличие от придурков типа Интеля) при развитии архитектур постоянно работает напрямую с пользователями.
И абстрактные вещи никогда не внедряет.
Так вот, задумайтесь, кому нужна свёртка с такими типами данных (вроде int4, например)?
При отсутствии поддержки даже float32.
Такое нужно только для одного из специфических подходов к ИИ, больше нигде.
И они — мировой лидер в этой области сейчас.
Возвращаясь к началу дискуссии — наши ребята сделали такой спецпроцессор без ненужной требухи, да ещё и в два раза более эффективный.
|
|
adolfus ( Слушатель ) |
| 12 ноя 2020 12:39:37 |
Цитата: dmitriк62 от 12.11.2020 11:00:32
Свертка нужна много где, и в первую очередь в HPC. А вот нейросети как "выскочили прыщом", так скоро и "засохнут". Как только с них состригут хайповые пенки, так и все. Просто вспомним, что перед нейросетями nvidia бешено стригла c "криптошахтеров". Где сегодня та крипта? Сегодня они суетятся с AI.
Что касается того, как nvidia работает с пользователями, мы это видим на НСКФ, где ее представители и представители AMD выступают на пленарных заседаниях.
А что касается российского спецпроцессора для MAA, будем надеяться, что разрядность мантиссы у него таки правильная, как указано в IEEE 754. Тогда это позволит ему держаться какое-то время на рынке. Кстати, эти самые "тензорные ядра" были во всех суперкомпьютерах конца 70-х – они составляли их архитектурный базис.
|
|
dmitriк62 ( Слушатель ) |
| 12 ноя 2020 12:54:11 |
Цитата: adolfus от 12.11.2020 12:39:37
Вы так и не ответили, где требуется свёртка с точностью 4, 8 или 10 битов.
А так-то да, свёртка с нормальной точностью — основа основ, но не для рынка Нвидии (в текущий момент).
(На НСКФ (как и вообще на любой форум) посылают маркетологов, обсуждения с разработчиками проходят по совершенно другим статьям).
|
|
adolfus ( Слушатель ) |
| 12 ноя 2020 14:16:01 |
Цитата: dmitriк62 от 12.11.2020 12:54:11
Как где? В ИИ. Поэтому там и точность, вернее уровень достоверности решения, соответствующий.

|
|
adolfus ( Слушатель ) |
| 12 ноя 2020 02:27:36 |
Цитата: dmitriк62 от 11.11.2020 09:55:26
Официальная документация nvidia – это "детсадовская элементарщина из учебника"?
Цитата: dmitriк62 от 11.11.2020 09:55:26
Сделано, чтобы матрицы с типом элемента FP32 перемножать с накоплением и без. Вот скриншот из https://developer.nvidia.com/blog/programming-tensor-cores-cuda-9/, где четко написано – "свертки и матричные операции" (convolutions & matrix ops.).

Специальный тип данных TF32 (для АИ) существует где-то на уровне микроинструкции умножения в контексте инструкции MMA и нигде не появляется вне блока MMA. Блок MMA получает на входе пару матриц FP32 и отдает на выходе матрицу FP32. У GA100 нет (см. формат регистровых полей ядра) места для хранения TF32 – в процессе ввода FP32 на векторные умножители мантисса у FP32 (IEEE 754 32 bit) обрезается до 10-и бит перед самим матричным умножением. результат умножения имеет формат FP32.
В мануалах и в статьях на сайте nvidia даже картинка есть на сей счет (Fig 9. на стр. 27). TF32 появляется в глубине MMA, там же и исчезает.
