50 лет на Луне. Факты.Техника. Юбилей
448,491
2,686
Карма: +66.62
Регистрация: 18.12.2012
Сообщений: 3,636
Читатели: 2
Регистрация: 18.12.2012
Сообщений: 3,636
Читатели: 2
Карма: -31.99
Регистрация: 12.11.2008
Сообщений: 3,165
Читатели: 1
Регистрация: 12.11.2008
Сообщений: 3,165
Читатели: 1
Цитата: normalized_ от 06.02.2018 19:05:54Бомбардир, дал исчерпывающе вводную.
Там клиент по Пирсону доказывал "корреляции" по минсоставу "материки" -"моря".
Потом Олег указал ему Вчера в 04:55 , что Луна-20 это материк, а не море, как считал до этого pmg натягивая очередную сову на глобус с помощью "Пирсона". (Сове при этом на глобусе было комфортно в обоих случаях).
Дальше pmg начал чесать репу "Бум думать",
Вообще-то то как он пользует (а точнее насилует) Пирсона это пипец на уровне 1-го курса по специальности статистка.
Других слов нет, и смех и грех. Впрочем я особо и не удивился, про корреляцию он давно чушь нес.
https://glav.su/foru…age4067064
А сегодня (прочитав наконец-то за N лет опровергательства ссылку на работы по грунту, и написав что-то типа "да, их оказывается много") написал, что придумал новый метод, но ему нужно еще данные.
Если Вы хотите ему объяснить про корреляцию, то конечно можно, ибо даже по старому его способу там же "ужас".
Я бы на его месте не изобретал бы велосипед как научный фрик (в теме в чем он посредственно разбирается), а просто ознакомился бы по теме статистики вообще (зачем она, когда применяют Пирсона и главное зачем), как сравнивают по признакам и зачем, по теме кластеризации и представлению признаков, по анализу выбросов, как проверяют гипотезы и по каким критериям в каких случаях, наконец как данные делают normalized и зачем.
Потому что то, что там "придумал" с Пирсоном это издевательство, которое сойдет, ну, может в физкультурном институте когда преподавателей заставляют рассчитывать статистику (для галочки, естественно), но уже никак не в т.н. "физкультурном техникуме" (физтехе) на котором он вроде бы учился.
Прикол в том, что корреляционный анализ, насколько мне позволяет вспомнить мой склероз, это метод (или инструмент, не помню уж) позволяющий установить статистическую зависимость между какой то там выборкой, заранее подготовленной по определённому правилу. В результате построения корреляционного поля можно оценить зависимость. Она или есть (сильная или большая штоле?) или её нет. Всё.
pmg, как любой опровергаст, прикручивает к, прости хоспади, ращёту заранее сформулированный тезис представляя его как вывод из ращёта, который он, якобы, в поте лица намастырил. Похожей методой пользуется электросекс Коновалов, который долго и нудно рассказывает как бы он снял ту или иную сцену (попёртую, кста, с фотографий НАСА, а не плод его креатива,) а в конце объявляет, что на основании его постановки, все фотки сняты в павильоне. Бггг...


Москва
Карма: +90.60
Регистрация: 07.06.2016
Сообщений: 5,219
Читатели: 17
Регистрация: 07.06.2016
Сообщений: 5,219
Читатели: 17
Цитата: Alexxey от 30.01.2018 01:27:47Все кресты на месте. Ещё раз прочитайте внимательно пояснение Evan Burton-у:Скрытый текст
Под прямыми лучами света от объектива на плёнке отпечатывается нормальное изображение креста, под переотражёнными в мерной пластине — искажённое/смещённое.
Вот чертёж "на глазок", но в приблизительном масштабе (исходя из расстояния между крестами 10 мм и толщины пластинки 4 мм).Скрытый текст
Такие искажённые кресты есть практически на всех фотках подобного рода. Чем ближе крест к центру Солнца, тем меньше смещение его искажённой копии. Собственно, тут даже можно точно посчитать расстояние между Reseau Plate и плёнкой.

P.S.
Пока свежачек в черновик по теме "Прожекторы":
Это фотографии Tesla Roadster, которые запостил Месикан под заголовком
штангели в небо, беглым фотошопом - огонь!



Цитата: ДядяВася от 07.02.2018 20:31:27Маска сюда не тащите, всё вытру.
ЦитатаЦитата: -=MeXicaN=- от 07.02.2018 22:12:25
тут ни слова про него, нет его фото, нет обсуждения чье-либо космонавтики. Зато здесь полно фотографий с Солнцем в кадре, с ореолами, гало и прочими артефактами оптики в вакууме. Что подтверждает тезис о сложности наблюдения звезд и Солнца в вакууме одновременно, дискуссия про данный "феномен" продолжается уже продолжительное время и пора подвести черту. Так как некоторые форумчане таки "сглазили" и появилась панорама в пять часов видео на котором любой желающий может померять засветы штангелем, потренироваться в фотошопе, тем более viewer через пару часов заспавнится.
Поскольку это очередной пример, что методика Вюерва по измерению Солнца штангелем мало соотносится с реальностью.
Отредактировано: normalized_ - 07 фев 2018 21:26:14
Москва
Карма: +90.60
Регистрация: 07.06.2016
Сообщений: 5,219
Читатели: 17
Регистрация: 07.06.2016
Сообщений: 5,219
Читатели: 17
Цитата: Пикейный жилет от 07.02.2018 14:52:41Илон Маск запустил мощнейшую в мире ракету Falcon Heavy на орбиту Марса
Школа "опровержения полетов не вставая с дивана":
Урок 1.
1. Да я вам сейчас покажу, что это всё можно подделать...
2. А какие изотопы?..
3. Что значит все?
4. А какие изотопы измеряли американцы?...
Написание опровержения заняло минуту.
На следующей неделе повторим урок...

Отредактировано: normalized_ - 08 фев 2018 10:07:19

Карма: +260.02
Регистрация: 05.08.2016
Сообщений: 18,954
Читатели: 4
Регистрация: 05.08.2016
Сообщений: 18,954
Читатели: 4
Цитата: normalized_ от 07.02.2018 20:49:04Поскольку это очередной пример, что методика Вюерва по измерению Солнца штангелем мало соотносится с реальностью.
И ещё одна зрадоперемога. Какого цвета "внатурирыжая" машинка Маска?

Зверей встретили песни и громкий смех.
А звери вошли и убили всех.
*****
Шприй был прав! (с)
А звери вошли и убили всех.
*****
Шприй был прав! (с)
Москва
Карма: +90.60
Регистрация: 07.06.2016
Сообщений: 5,219
Читатели: 17
Регистрация: 07.06.2016
Сообщений: 5,219
Читатели: 17
Цитата: Vick от 07.02.2018 23:54:22И ещё одна зрадоперемога. Какого цвета "внатурирыжая" машинка Маска?Скрытый текст
Сложно так, на взгляд, сказать...

Кажется этот, обвел кружочком:

Но тут сложно сказать.
Тут вот не понятно, какая часть кольца светлее, а какая темнее?
(От фона неба зависит) А RGB одинаковый...
А тут в верхнем ряду красные полоски слева имеют тот же RGB что и полоски справа (а кажутся красными и фиолетовыми соответственно)

А в нижнем ряду на рисунках полосы которые кажутся светлозелеными и голубыми соответственно, тоже имеют одинаковый RGB.
(зависит от рядом эталонных цветов)
Да и грунт (ильменит или магнетит) на земных фото, то ли серый (на фоне с мусором) то ли он все таки черный как уголь (в руке), то ли он серо бурый, если присмотреться.

В общем без спектра отражения как сказал Д,В. нельзя точно о цвете говорить.
Отредактировано: normalized_ - 08 фев 2018 00:56:10

Москва
Карма: +884.18
Регистрация: 21.03.2013
Сообщений: 27,822
Читатели: 7
Регистрация: 21.03.2013
Сообщений: 27,822
Читатели: 7
Цитата: Пикейный жилет от 07.02.2018 14:52:41Илон Маск запустил мощнейшую в мире ракету Falcon Heavy на орбиту Марса
Она будет мощнейшей, когда выведет наибольший груз и не взорвётся от натуги.
Империя - это мир, и этой идеологии достаточно. Мы живём в самой лучшей стране в мире и все нам завидуют.
Одушевлённое Одевают, Неодушевлённое Надевают.
Одушевлённое Одевают, Неодушевлённое Надевают.
Карма: +66.62
Регистрация: 18.12.2012
Сообщений: 3,636
Читатели: 2
Регистрация: 18.12.2012
Сообщений: 3,636
Читатели: 2
Цитата: slavae от 08.02.2018 04:42:42Она будет мощнейшей, когда выведет наибольший груз и не взорвётся от натуги.
 Смотрите сами не взорвитесь от натуги опровергательства.
Смотрите сами не взорвитесь от натуги опровергательства.НОО
СССР - Россия
Энергия - 100т - 2 запуска
Ангара - 35 т - 2 запуска
НОО
США
Сатурн 5 - 140т - 13 запусков
Falcon Heavy - 63 т - 1 запуск
Отредактировано: Пикейный жилет - 08 фев 2018 15:10:33
Москва
Карма: +90.60
Регистрация: 07.06.2016
Сообщений: 5,219
Читатели: 17
Регистрация: 07.06.2016
Сообщений: 5,219
Читатели: 17
Цитата: Пикейный жилет от 08.02.2018 14:46:06
НОО
СССР - Россия
Энергия - 100т - 2 запуска
Ангара - 35 т - 2 запуска
НОО
США
Сатурн 5 - 140т - 13 запусков
Falcon Heavy - 63 т - 1 запуск
К слову "Как опровергнуть Сатурн-5 не вставая с дивана"
Цитата: EugenL от 07.02.2018 14:39:27"Ракета «Сатурн-5» ... могла вывести на низкую околоземную орбиту 141 т (эта масса включает в себя корабль «Аполлон» и массу последней ступени с остатками топлива для разгона к Луне)..."
.
" Falcon Heavy ... Планируется, что носитель сможет доставлять до 63,8 т на низкую опорную орбиту, до 26,7 т на геопереходную орбиту ..."
.
Именно поэтому обсуждаем Сатурн-5 в 1969, а не Фалкон в 2018.
Очень просто. Надо сказать хрень, но ни в коем случае не смотреть на стартовую массу:
Falcon Heavy - 1421 тонны
Сатурн-5 . - 2290 тонны
Для натягивания совы на глобус это лишнее.
И тогда тем более не нужно обременяться лишними понятиями и знаниями о §Пропорции, 6 класс
Конец урока.
57 лет
Карма: +161.58
Регистрация: 17.04.2009
Сообщений: 6,569
Читатели: 30
Регистрация: 17.04.2009
Сообщений: 6,569
Читатели: 30
Цитата: slavae от 05.02.2018 23:21:36Я даже не буду спрашивать, честно. Потому что представитель ОТК так же далёк от разработки, как американский конструктор Аполлона от реальных полётов. Шатл возили на самолёте год, если что.
И на том же самолёте, что ли, проверяли:
- систему разделения ТТУ и основного бака;
- систему разделения бака и самолета;
- виброустойчивость в условиях объектовых вибронагрузок всех систем и агрегатов корабля;
- работоспособность бака в условиях объектового скоростного напора и объектовых тепловых нагрузок;
- работоспособность ТТУ в условиях объектового скоростного напора и тепловых нагрузок;
- импульс последействия ТТУ;
- скоростной напор и тепловые нагрузки на самолёт при посадке...
Это только что за пять минут вспомнилось. Еще разок, для особо альтернативно одарённых опровергов, можно было сажать людей на такую "недоиспытанную машину" или нет?
Цитата: slavae от 05.02.2018 23:21:36Если корабль даже не может выполнить экспериментальную программу полёта, то только ангажированный человек будет восторгаться полным запуском. Нормальный-то человек схватится за голову – ой бл.. идиоты.. что ж вы делаете..
Только конченный дебил склонен раздавать массу бесполезных советов ответственным и профессиональным людям. Только совершенно упоротый дятел не в состоянии сформулировать чем "экспериментальная" машина отличается от штатной. Потому, что он тупой и не знает, что порядок отнесения изделий к "экспериментальным или "штатным" или "серийным" исчерпывающее и однозначно описан в соответствующей руководящей документации. Шаттл, лапочка, был экспериментальным или как?
Цитата: slavae от 05.02.2018 23:21:36Ну а вы давайте. Ещё там пендосии посоветуйте всякие там Драгоны и Орионы после крушения сразу с людьми к Луне запускать. Это ж самое то! Интересно услышать ответ.
Нахрена тебе ответ? Он же тебе точно не понравится...Через пару лет, полетят люди на Драгонах или Орионах. А ты будешь сидеть и ждать аварий, что бы испытать свой "патриотический" оргазм от чужой трагедии. Только не будет аварий, они будут летать, а персонально ты будешь страдать и чахнуть...
Цитата: slavae от 05.02.2018 23:21:36А ещё интересно от наших услышать ответ. Рухнет Федерация, а его сделают с доработками, и сразу к Луне с людьми. О будет цирк, как на Перегрева и прочих идиотиков будут охотиться.
Вообще не понял о чём Вы. Кто будет охотиться, на кого, зачем.... С Вами точно всё в порядке?
Цитата: slavae от 05.02.2018 23:21:36PS Перегрев, дорогой, не в обиду. Ты на меня уже три раза наехал в космической ветке, типа ты такой спец в разработке, что там шпаки нам советовать будут.
А где я не прав? Я действительно спец, а ты анонимный лузер ни бельмеса не понимающий в вещах о которых с непростым жалом берешься рассуждать.
Цитата: slavae от 05.02.2018 23:21:36Но Оля из ОТК не может быть разработчиком, даже если она очень близко общается с главным конструктором.
Ты брателло вообще ничего не знаешь про тётю Олю из ОТК. Она может и не разработчик, но она очень важных участник процесса разработки. Ты просто никогда не видел, как доктора наук просят тётю Олю промерить профиль. Знаешь как это выглядит?
Главный конструктор (ГК): "Ольга Петровна, (Ольга Петровна – массивная женщина лет 57) вот у нас здесь улитка, вот ту что на порезку, запороли, вот тут, вот нам бы, вот бы померить..."
Ольга Петровна (ОП): "Василич, да ты охренел? Как я тебе померяю? Базы в чертеже нет, все размеры в чертеже "висячие", шаблон обещали сделать, не сделали... Как???"
ГК: "Ну, Оля Петровна, ну, по старой дружбе, ну помнишь как мы на 158й машине тогда, ну выручай!"
ОП: "Да что я там намеряю...." (размещается на стуле, тихо про себя матерясь, что-то меряет микрометром на стойке, что-то пишет на бумажке, что-то считает на калькуляторе в стареньком телефоне...)
Часа через полтора
ОП: "Ну вот"
ГК: "Вот спасибо! А здесь точно столько?"
ОП: "Василич!!!!, ..... бля......!!!!!!"
ГК: "Понял, понял, спасибо"
Потом после огня, померяли на КИМ, выяснили, что тётя Оля геометрические величины измеряет немногим хуже забугорной машины за многие десятки миллионов.
Всё к чему, братан, если ты хотел меня унизить сравнением с тётей Олей из ОТК, то трагически и масштабно промахнулся. Я таким сравнением горжусь. Лучше быть тётей Олей из ОТК, чем таки безграмотным балаболом как ты.

Цитата: slavae от 05.02.2018 23:21:36Да и у меня терпение тоже не безграничное.
Я Вам открою один маленький секрет. Границы Вашего терпения меня, да и всех форумчан, интересуют чуть менее, чем никак.
"Военное дело просто и вполне доступно здравому уму человека. Но воевать сложно."
К.Клаузевиц
К.Клаузевиц
Карма: +66.62
Регистрация: 18.12.2012
Сообщений: 3,636
Читатели: 2
Регистрация: 18.12.2012
Сообщений: 3,636
Читатели: 2
Цитата: viewer от 08.02.2018 20:06:11С орехметекой это к корнею. И не забудьте упомнить о §Средние величины. 5 класс. Именно этими лишними понятиями и знаниями он и необременён.

Уважаемый модератор.
Прошу сносить на этой ветке все посты вивера.
Он не извинился за хамство по поводу смерти астронавта.
Повод не проблема.
Намеренное искажение НИКа, намеренное искажение русского языка.
То есть хамство по отношению к участникам этой ветки.
Идеальный вариант постоянный БАН на этой ветке до принесения извинений.
Карма: -31.99
Регистрация: 12.11.2008
Сообщений: 3,165
Читатели: 1
Регистрация: 12.11.2008
Сообщений: 3,165
Читатели: 1
Цитата: viewer от 08.02.2018 20:06:11С орехметекой это к корнею. И не забудьте упомнить о §Средние величины. 5 класс. Именно этими лишними понятиями и знаниями он и необременён.
А с зенитным прожектором к тебе?

Москва
Карма: +90.60
Регистрация: 07.06.2016
Сообщений: 5,219
Читатели: 17
Регистрация: 07.06.2016
Сообщений: 5,219
Читатели: 17
Цитата: BomBarDir от 07.02.2018 16:17:57Прикол в том, что корреляционный анализ, насколько мне позволяет вспомнить мой склероз, это метод (или инструмент, не помню уж) позволяющий установить статистическую зависимость между какой то там выборкой, заранее подготовленной по определённому правилу. В результате построения корреляционного поля можно оценить зависимость. Она или есть (сильная или большая штоле?) или её нет. Всё.
Пирсон если "1" или "-1" то сильная корреляция (или отрицательная корреляция, тоже связь), а именно мера линейной зависимости. Если 0, то корреляции нет.
Но нужно учитывать, что из корреляции не обязательно следует причинно-следственная связь (а вот где есть связь, там часто обнаруживается корреляция). То есть существуют так называемые ложные корреляции.
В учебниках часто дают веселые примеры:
а) случайные совпадения
Например данные о количестве людей, утонувших в бассейне и количеством фильмов, в которых снялся Николас Кейдж.
Или
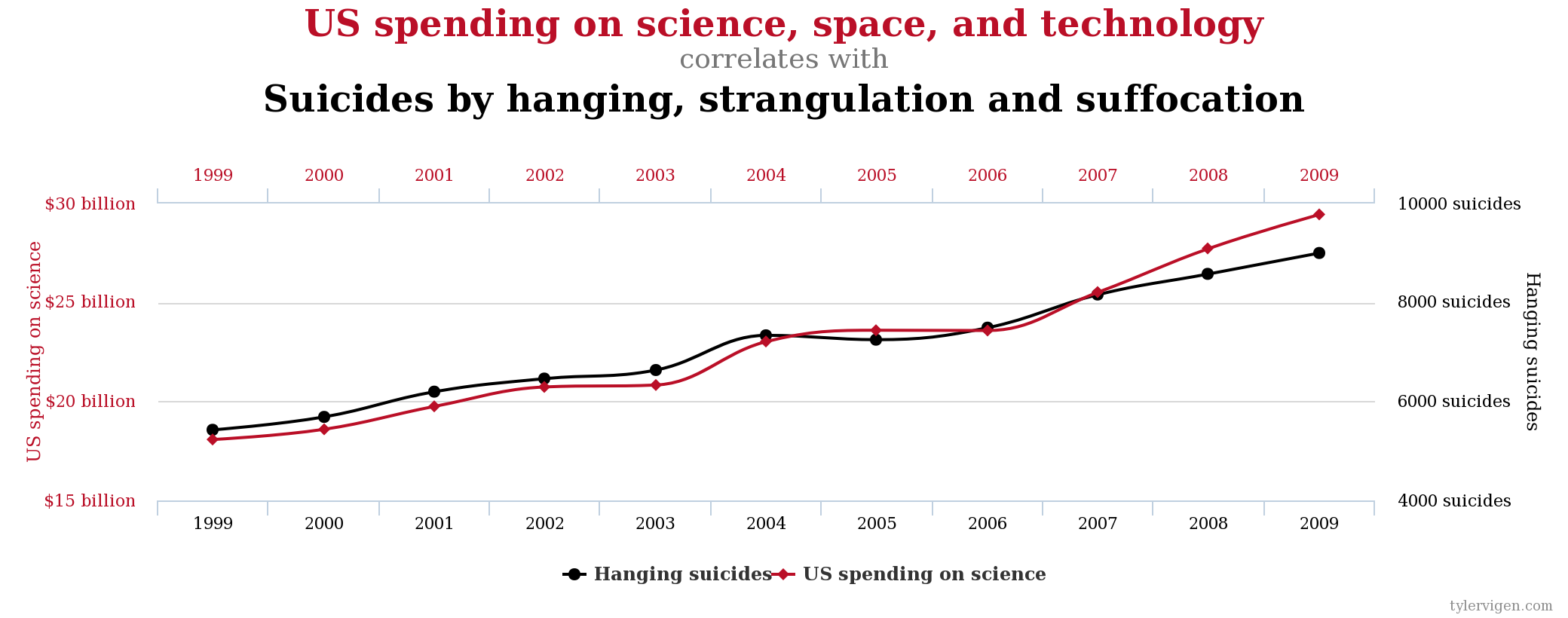
Затраты США на науку, космос и технологии / Суициды путем повешения и удушения. Корреляция 99,79%.
Доля разводов в штате Мэн / Среднее потребление маргарина. Корреляция 99,26%
.png)
Тут еще "Безумные корреляции":
http://rationalnumbe…rrelyacii/
б) Есть корреляции объясняющихся воздействием третьего скрытого признака.
Например, количество самоубийств и кол-во радиоприемников на душу населения сильно положительно коррелировано (воздействие скрытой связи "размер города")
Или есть корреляция: чем больше продается мороженного на пляже, тем больше утопленников.
корреляция (на каком то пляжу где записывали данные) слабая 0,33, но имеется.

Можно, конечно, сразу делать вывод опровергательстких масштабов: то ли чем больше едят мороженного, тем чаще тонут от переизбытка сладости, то ли раз чаще тонут, то другие больше едят мороженное на нервной почве наблюдая праздно за шумихой. Но на самом деле есть скрытая третья переменная, через которою есть связь (температура)
Кроме этого нужно избегать других неточностей.
1. Во первых, автор сравнивает коэффициенты корреляции (как меру похожести) по отношению только к одним опорным данным (выборкой это назвать сложно, но об этом ниже ) — по Луне-16 — а не сравнивает миссии попарно.
Это аналогично тому, что при сравнении "близости" разных точек О, A и B на плоскости, сравниваются только их расстояния до одной точки О.
Чисто геометрически, даже если "расстояния" ("похожести") до основной точки будут одинаковые (т.е. расстояние OA примерно равно OB), ничего нельзя сказать о похожести AB (они могут быть как далеко друг от друга, на противоположенных сторонах окружности вокруг О, так и рядом).
2. Как указано по ссылке (данной Выше) автор не совсем понимает, что такое корреляция и почему, например, коэффициент корреляции между измерениями:
одного ученого: 1, 2, 3
и другого: 50, 80, 150.
будет вообще аж 0.974! Но это не означает равенства (и верности, и схожести) измерений между этими данными.
Корреляция лишь отражает линейную зависимость (и возможную связь), а не равенство.
3. Не делают корреляцию вдоль разнородных данных (процентовок разных оксидов, слонов и попугаев).
Коррелируют или выборки,
а) скажем берут 10 миссий, смотрят для них корреляцию оксида Магния (10 значений) или Марганца (10 значений). Для установки зависимости между одним элементом или другим .
б) Или делают сравнение или проверку гипотез ставя те или иные вопросы.
Например, берут выборки 5 миссий (марганца) и 10 миссий (тоже марганца) и отвечают на вопрос (проверяют гипотезу) равны ли средние выборок (или же просто случайно отличаются). Для этого применяют критерии. Причем если известно распределение и его параметры то параметрические, если нет, то непараметрические критерии. И там тоже есть всякие нюансы.
(об этом ниже)
4. Дальше, если просто смотреть на цифры (понимая по предыдущему пункту, что нельзя сравнивать разнородные признаки корреляцией вдоль них), то можно заметить, что минералы со концентрациями близким к 0% практически не участвую в оценке коэффициента корреляции. (Оксиды марганца, калия, натрия)
На графике они около точки 0 и наложились друг она друга.

Они могут отличаться хоть в 10 раз (между миссиями) но сильно от этой нулевой точки не уйдут. Прямая это не "почувствует". Их изменение не влияет на вычисленный коэффициент Пирсона. Меняй хоть в 10 раз оксиды натрия или марганеца. Пирсон покажет, что образцы практически так же "похожи"
Можно это заметить, что если убрать эти оксиды из данных, то останутся точки которые сильнее разбросаны от прямой. За счет сокращения базы среднего, коэффициент уменьшится.

И наоборот, если добавить оксиды "серебра" золота" (нулевые точки причем хоть одинаковые, хоть отличающиеся в 10 раз, но они при этом все равно малые, около нуля), то КП увеличится (кол-во точек будут уменьшать среднее "отличий")

6) Чтоб обрабатывать задачу желательно
- сделать визуальное представление данных о чем речь (обзор)
- похожесть сравнивать попарно
- нормировать данные (при вычислении похожести)
- для сравнения попарно нужно выбрать измерение "похожести". Коэффициент корреляции не единственный, можно применять другие метрики "расстоянии" (например cosine или евклидово)
- попробовать представить на плоскости (понижение пространства) чтоб посмотреть, кто более с кем похож визуально, кластеры и выбросы.
- проверять те или иные гипотезы по тем или иным признакам.
В качестве примера. (И для небольшой разминки)
Воспользовавшись исходными данными автора из 05 февраля 2018,
| i | mission | type | SiO2 | Al2O3 | TiO2 | FeO | MgO | CaO | Na2O | K2O | MnO |
| 1 | Л16 | Море | 41.70 | 15.33 | 3.39 | 16.64 | 8.78 | 12.49 | 0.34 | 0.10 | 0.21 |
| 2 | Л20 | Горы | 44.20 | 22.90 | 0.56 | 7.03 | 9.70 | 15.20 | 0.55 | 0.10 | 0.12 |
| 3 | Л24 | Море | 43.30 | 15.20 | 1.13 | 16.30 | 8.69 | 13.10 | 0.42 | 0.04 | 0.22 |
| 4 | A11 | Море | 41.90 | 13.55 | 7.56 | 15.94 | 7.82 | 12.08 | 0.40 | 0.13 | 0.21 |
| 5 | A12 | Море | 45.90 | 12.50 | 2.81 | 16.40 | 10.00 | 10.40 | 0.41 | 0.25 | 0.22 |
| 6 | A14 | Горы | 47.20 | 17.20 | 1.79 | 10.40 | 9.37 | 11.00 | 0.66 | 0.58 | 0.14 |
| 7 | A15 | Море | 47.07 | 14.17 | 1.75 | 14.92 | 10.44 | 8.95 | 0.39 | 0.20 | 0.18 |
| 8 | A16 | Горы | 45.17 | 26.71 | 0.59 | 5.57 | 6.03 | 15.61 | 0.44 | 0.12 | 0.08 |
| 9 | A17 | Море | 40.37 | 11.60 | 8.99 | 17.01 | 9.79 | 10.98 | 0.32 | 0.08 | 0.23 |
Понятно, что сами исходные данные агрегированы (то есть уже усреднены) и нтересней было бы иметь больше данных, чтоб делать открытия (не в кавычках).
Тем не менее для небольшого урока и разминки:
Общая картина

Разбивка по типу (Суша или море)

Так как оксиды с низким содержанием плохо видны, то отобразим их отдельно

Черный отрезок визуализирует средне квадратичное отклонение.
Справа Violin_plot аналог Бокс-Плота (ящики с усами) только с KDE
Так как автор пытался осмыслить корреляцию концентраций, посмотрим их попарное соотношение визуально.
(Примечание: делать выборку разнородных величин, как указано выше, не верно, но посмотреть можно)

Столбцы и строки на графике соответствую миссиям.
В ячейках правого верхнего угла нарисовано распределение оксидов соответствующей пары миссий
В нижнем левом углу тоже самое с вычисленными коэффициентами Пирсона, и вычисленная линейная регрессия (не имеет к Пирсону прямого отношения, например она не обязательно проходит через точку 0).
Отдельно по морям

Отдельно по материкам

Корреляционная матрица
На попарных графиках выше мы посмотрели на данные, но они в данном случае разбросаны и не информативны (а вот в реальных задачах с выборками уже могут появиться идеи и наблюдения как обрабатывать дальше), за деревьями леса не видно.
Поэтому отдельно посмотрим на корреляционную матрицу.
Опять же примечание: что "выборка" по разнородным данным, но мы тут исправляем "недочет" автора не использующего попарное сравнение коэффициента корреляции.

В цифрах: mc_corr_pearson_all.csv (Собственно, автор смотрел только на одну строку из этой матрицы)
Матрица симметричная (относительно диагонали) и цвет ячеек соответствует коэффициентам корреляции между миссиями.
Чем темнее ячейки, тем больше коэфф. Пирсона между соответствующими парами.
(опять замечание, что между разнородными кучами попугаев и ежей)
Тем не менее тут уже кое что можно заметить.
Например, Луна-20 больше всего "совпадает" с Аполлон-16.
Все они сильно "коррелируют" (левая картинка темная), самые непохожие пары имеют коэффициент 0,861
К слову, кроме Пирсона можно использовать и ранговые корреляции (они меньше чувствительны к выбросам) Спирмена и Кендела
Соответствующие корреляционные матрицы


Теперь отобразим отдельно Горы и Моря
(можно было бы сгруппировать автоматически по данным матрицам, то есть кластеризовать, с тем или иным параметром число групп)


Внутри каждой из этих групп пары коррелируют сильнее, нет пар с коэффициентом корреляции меньше 0,9773 и 0,9603 соответственно, тогда как на общей корр. матрице минимум 0,8681.
Визуально это заметно тем, что на левой части практически нет таких светлых ячеек как на общей матрице.
Это собственно то, что должен был корректно продемонстрировать автор по своему методу (исправлена ошибка не попарного сравнения).
Проверка гипотез.
(в качестве примера, что можно сравнивать однородные данные) вернемся к графику:
Скрытый текст
Видно, что для некоторых оксидов есть подозрение на статистическое отличие между материками и морями
Проверим это формально на примере SiO2.
Содержание SiO2
В морях: 41.7 , 43.3 , 41.9 , 45.9 , 47.07, 40.37
На суше: 44.2 , 47.2 , 45.17
Можно было бы применить критерий Стьдента для проверки гипотезы значимого отличия средник, но перед этим мы должны проверить, а нормальное ли распределение.
Для этого сначала визуально проверим вероятностные графики, а потом применим критерий Шапиро-Уилка.

На прямой точки лежат не близко, уже подозрения.
Критерий Шапиро-Уилка
- H0: Кол-во SiO2 (в выборках суша и море) распределены нормально
- H1: не нормально.
Задаем уровень значимости alpha 0.05 (95.0% уровень доверия)
Проверка Shapiro-Wilk 'Море': W-statistic: 0.92456138134, p-value: 0.538803696632
Отвергаем гипотезу H0
Тоже самое для Гор:
Проверка Shapiro-Wilk 'Море': W-statistic: 0.92456138134, p-value: 0.538803696632
Отвергаем гипотезу H0
Гипотезу о нормальности выборок отвергаем, так как p-value большое (больше 0.05)
Критерий Стьюдента применить нельзя.
Поэтому применяем непараметрический критерии [ например U-критерий Манна — Уитни]
MannwhitneyuResult(statistic=4.0, pvalue=0.1226390584033864)
pvalue больше уровня значимости
Гипотезу о том, что выборки (SiO2 для гор и морей) не отличаются, отвергнуть нельзя.
Теперь тоже самое на примере оксида алюминия Al2O3.

Критерий Шапиро-Уилка. Гипотезы
- H0: Уровень Al2O3 (в выборках суша и море) распределены нормально
- H1: не нормально.
Задаем уровень значимости alpha 0.05 (95.0% уровень доверия)
Проверка Shapiro-Wilk 'Море': W-statistic: 0.937569320202, p-value: 0.639681518078
Отвергаем гипотезу H0
Проверка Shapiro-Wilk 'Море': W-statistic: 0.937569320202, p-value: 0.639681518078
Отвергаем гипотезу H0
Так как p-value большое (больше 0.05) отвергаем гипотезу о нормальности.
Критерий Стьюдента применить нельзя.
Поэтому применяем непараметрический критерии [U-критерий Манна — Уитни]
MannwhitneyuResult(statistic=0.0, pvalue=0.014092901073953692)
Гипотеза о том, что выборки не отличаются можно отвергнуть в пользу гипотезы что средние концентрации Al2O3 отличаются.
Это можно заметить (подозревать) и визуально и на выше приведенном графике.
Замечание:
При больших объемах, например когда проверяют гипотезы и сравнивают влияние генов и очень большого ко-во гипотез, то проводят множественную проверку.
Например, если тестировать отличия по большому объему данных и очень много гипотез, то рано или поздно возможно случайное отклонения измерений.
Один из примеров (другие по ссылке). Американский психолог и парапсихолог Джозеф Райн, который занимался исследованиями экстрасенсорных возможностей разных людей, проводил следующие эксперименты. На первом этапе он делал предварительный отбор.
Испытуемому давали 10 карт, и он должен был угадать их цвета.
Оказалось, что два человека все 10 карт угадали, еще девять человек угадали 9 из 10 карт.
Но по этим данным нельзя делать выводы, что экстрасенсорные способности проявились, так как число испытаний было большим 1000 человек.
Из такого кол-ва рано или поздно кто-то из людей угадает случайно.
После того как Джозеф Райн отобрал этих людей, угадавших цвета карт, как экстрасенсов, он предложил им еще раз пройти этот эксперимент . Ни один не подтвердил свои способности.
Отсюда Джозеф Райн сделал вывод, что если человека объявить экстрасенсом, то его способности сразу пропадают.
Можно посмотреть на график вероятности, что хотя бы один угадает цвета 9 из 10 карт в зависимости от количества испытуемых

Видно, что вероятность растет быстро, уже при 100 испытуемых вероятность найти одного экстрасенса больше 0,5, а при больших количествах испытуемых вплотную приближается к 1, очень вероятно что кто-то угадает.
Для нивелирования эффекта множественности и вероятности ошибки "хорошего промаха" (ошибки первого рода), при проверке множественных гипотез можно уменьшать уровень значимости 0.05 пропорционально кол-ву в группе (Поправка Бонферрони), но есть и другие методы.
Вот такое короткое замечание...
Понижения размерности
Для кластеризации данных мало, но можно посмотреть как соотносится состав грунта от миссии к миссии.
Формально будем считать, что у каждой миссии есть несколько признаков (в данном случае вещественных) как концентрации 9 оксидов.
Представим эти 9 признаков в пространстве размерности 2 (для визуализации на плоскости).
В первою очередь проведем нормализацию данных (т.е. отмасштабируем или стандартизируем) мелкие концентрации повысим, и выравним масштаб и смещение, чтоб все были с одинаковым СКО).
Для начала используем ранговый метод tSNE

На этапе визуализации подсветим сушу и море разными цветами.
(Этот график не единственное точное отображения, так как определяется случайностью)
Ничего тут особо не скажешь, Луны разбросаны и Аполлоны тоже.
Теперь MDS.
Для него в качестве вспомогательной метрики (отличие между признаками) можно использовать "расстояния".
Вот одним из вариантов этой метрики и может выступать матрица корреляции (но уже по стандартизированным данным вдоль миссий )

Для больших данных часто применяют cosine расстояния между признаками, или евклидово:
Скрытый текст


Вот по всем этим метрикам можно заметить зачатки двух кластеров: моря и суши. (А то и три)
Но как писалось выше, когда мало данных, то не очень интересно. Можно было бы делать и другие картины, считать (обнаруживать), ставить вопросы и их делать оценки, есть ли выбросы, которые могут быть примечательными особенностями, естественные, интересные или обнаружить открытия.
Выводы
Рекомендация автору: чем изобретать велосипед применяя чистый разум (т.е. не отягощенный знаниями) и путаться в трех соснах в бесплодных попытках опровергать полеты не вставая в дивана, сначала полезней ознакомиться с тем, что давно до него изобрели умные люди, и вообще со статистикой.
http://baguzin.ru/wp…chnye-kri/ (всю книгу)
Или по профилю:
Биостатистика и язык R: Понижение размерности: PCA, MDS, t-SNE
Цитата: BomBarDir от 07.02.2018 16:17:57pmg, как любой опровергаст, прикручивает к, прости хоспади, ращёту заранее сформулированный тезис представляя его как вывод из ращёта, который он, якобы, в поте лица намастырил. Похожей методой пользуется электросекс Коновалов, который долго и нудно рассказывает как бы он снял ту или иную сцену (попёртую, кста, с фотографий НАСА, а не плод его креатива,) а в конце объявляет, что на основании его постановки, все фотки сняты в павильоне. Бггг...
У меня сложились очень похожие впечатления.
Отредактировано: normalized_ - 09 фев 2018 15:34:36
Карма: -31.99
Регистрация: 12.11.2008
Сообщений: 3,165
Читатели: 1
Регистрация: 12.11.2008
Сообщений: 3,165
Читатели: 1
Цитата: normalized_ от 09.02.2018 11:44:02Пирсон если "1" или "-1" то сильная корреляция (или отрицательная корреляция, тоже связь), а именно мера линейной зависимости. если 0, то корреляции нет.
Но нужно учитывать, что из корреляции не обязательно следует причинно-следственная связь (а вот где есть связь, там часто обнаруживается корреляция). то есть существуют так называемые ложные.
В учебниках часто дают веселые примеры:Скрытый текст
Камрад, снимаю шляпу. Вернулся во времена своей юности и испытал давно забытое ощущение невероятного облегчения от того, что наконец то отмучил 2 пары и семинар по матстату. И можно с друзьями и подругами, с чистой совестью, завалиться в кафешку "Лакомка" и под пироженные "Картошка" с "Портвейном" (взятым, есессно по пути в ""Лакомку") впасть в полное забытиё перед завтрашней парой лекций по ненавистному матстату.
Жаль только одного, опровергасты даже читать не станут. У них уже есть готовый вывод, так что некуй читать многАбукав.
Уволоку к себе такую полезняшку. А вы говорите опровергасты никакой пользы не приносят! Ты посмотри какого Пегаса тебе прислал pmg. Без него ты бы сроду ничего подобного бы не родил.

ЦитатаУ меня сложились очень похожие впечатления.
Это, друг мой, не впечатление...Это осязаемая реальность.
[/quote]
Отредактировано: BomBarDir - 09 фев 2018 13:51:28
Москва
Карма: +90.60
Регистрация: 07.06.2016
Сообщений: 5,219
Читатели: 17
Регистрация: 07.06.2016
Сообщений: 5,219
Читатели: 17
Цитата: BomBarDir от 09.02.2018 13:48:24Камрад, снимаю шляпу. Вернулся во времена своей юности и испытал давно забытое ощущение невероятного облегчения от того, что наконец то отмучил 2 пары и семинар по матстату. И можно с друзьями и подругами, с чистой совестью, завалиться в кафешку "Лакомка" и под пироженные "Картошка" с "Портвейном" (взятым, есессно по пути в ""Лакомку") впасть в полное забытиё перед завтрашней парой лекций по ненавистному матстату.
Жаль только одного, опровергасты даже читать не станут. У них уже есть готовый вывод, так что некуй читать многАбукав.
Уволоку к себе такую полезняшку. А вы говорите опровергасты никакой пользы не приносят! Ты посмотри какого Пегаса тебе прислал pmg. Без него ты бы сроду ничего подобного бы не родил.
Это, друг мой, не впечатление...Это осязаемая реальность.
Спасибо, что читаете.
Ну я как раз больше для себя (в качестве упражнения) и для нормальных писал, чем для него.
К сожалению Перегрев в запарке, а то бы и он еще больше приложил. И веселее.
А так не трудно, сейчас библиотеки есть и по визуализации и по расчетам. И все это известно. Там самое сложное, что нужно иметь представление, что бывают такие-то понятия, и держать в голове, что нужно не забыть проверить это и это.
Просто при чтении разбираемого автора у меня волосы на голове встали, куда он лезет? Я еще понимаю, чудак который вообще ничего не знает (и не хочет знать) про космические полеты и как их делают и испытывают технику, но разбираемый автор же институт кончил вроде неплохой, пусть и "упался" на опровергательтсве. Если ему просто написать "у тебя тут ошибка, вот", то он это все равно же пропустит мимо ушей из-за тенденция селективного восприятия. И даже не поймет насколько глубоко ошибается ("подумаешь, ошибка, первый раз что ли? При опровержении полетов это дело житейское, обычное и ежедневное, в главном то все равно прав. главное то отряхнуться как ни в чем не бывало, и опровергать дальше", подумает он. Забудет все равно, и опять вылезет через неделю с тем же самым или подобным бредом.
А вообще статистика (и не только) дело интересное, но там не просто прикол, что графики нарисовать (это просто "пощупать" данные с разных сторон, с чего начать их изучать) или бездумно что-то посчитать, среднее или показать "рост". Там самое интересное, что нужно ответить на некоторый вопрос (не все вопросы), например стоит ли принимать такое то решение или не стоит.
Причем ответить на него нужно объективно, воспроизводимо, точно, обосновано, а не кулуарно, и в тоже время не случайно, как бог на душу положит или по своим личным предпочтениям (Хотя и есть правда, что статистику можно натягивать на глобус, и в некоторых вопросах должна быть этика, вот поэтому ее тоже нужно знать)
Собственно поэтому это "оружие" более ста лет назад и не давали публиковать тому самому "студенту". Ибо для производителя пива Гинесс критерии принятия решений в селекции ячменя считалось коммерческой тайной, о которой не должны были знать конкуренты.
Сейчас, конечно, решения не только на основе критериев должны применяться (смотря какие), но в простейших вещах не должно быть ошибок в обоснованиях.
Отредактировано: normalized_ - 09 фев 2018 20:57:43
ДВ
Карма: +51.33
Регистрация: 15.11.2015
Сообщений: 632
Читатели: 0
Регистрация: 15.11.2015
Сообщений: 632
Читатели: 0
Господа!
А особенно, господин перегрев. Прокомментируйте, пожалуйста!
К юбилею, я считаю, самое оно.
З.Ы. Могу сфотать панель управления станка с УЧПУ после 5 лет эксплуатации в две, иногда и в три!, смены - состояние один-в-один!
А шкаф электроавтоматики выглядит гораздо лучше!
А особенно, господин перегрев. Прокомментируйте, пожалуйста!
ЦитатаИ детали (панели) с раздолбанной краской в местах креплений, и провода оборванные лейкопластырем перемотаны -
и ничего себе, летит - попёрдывает.
Это А-11. ЛМ изнутри AS11-36-5399
Проверка систем перед прилунением. Изготовлено на первом в мире «чистом производстве».
"Это просто какой-то позор!" (с)
Особенно умиляют торчащие провода. А дело-то, по легенде, происходит в невесомости, где нет надежной опоры, да и координация выкидывает разные неприятные фокусы. Махнул рукой, оторвал провода, дуга в атмосфере чистого кислорода с примесью кишечных газов, неизбежно присутствующих в кабине ввиду "гениальной" ассенизационной системы на целлофановых пакетах, приклеиваемых к волосатым задницам в процессе дефекации, и ....
Да и остальное - грязища, отсутствие винтов, скоч на проводах, протертое до металла ЛКП, общая "культура" производства неумолимо говорит, что это всего лишь обыкновенный реквизит, не более того. Причем сделанный похабно даже для реквизита. Возможно по причине существования, в том числе, и таких вот залепух Алексей Архипыч говорит о досъемках. Вот как ему еще объяснить свою "веру" в полеты, если кто-нибудь вроде Пушкова тыкнет его носом вот в это лунотворчество?
Но есть такие, кто верит. Кстати, показательно очень было бы заслушать по данному вопросу мнения местных защитников.
Итак, господа, вот эти вот фото постановочные ("доснятые", если хотите) или нет, вот это и в самом деле летело к Луне?
Итак, господа, хватит демагогии. Прошу высказываться.
P.S. Отсутствие высказываний однозначно засчитывается за слив.




К юбилею, я считаю, самое оно.
З.Ы. Могу сфотать панель управления станка с УЧПУ после 5 лет эксплуатации в две, иногда и в три!, смены - состояние один-в-один!
А шкаф электроавтоматики выглядит гораздо лучше!
Отредактировано: Gremlin - 10 фев 2018 02:34:36
Карма: +66.62
Регистрация: 18.12.2012
Сообщений: 3,636
Читатели: 2
Регистрация: 18.12.2012
Сообщений: 3,636
Читатели: 2
Цитата: Gremlin от 10.02.2018 02:28:20Прокомментируйте, пожалуйста!
Друзья.
У кого есть желание разговаривать с этим автором, пожалуйста на другой ветке.
Спасибо за понимание.
Москва
Карма: +90.60
Регистрация: 07.06.2016
Сообщений: 5,219
Читатели: 17
Регистрация: 07.06.2016
Сообщений: 5,219
Читатели: 17
Цитата: лателеннолоппа от 10.02.2018 13:27:46Им нечего сказать. Включая г-на Сеню, который не только покрывает юбиляров, но и снимает минусы с постов техников. Афёра продолжается, так или иначе, продолжайте . господа, продолжайте лицедействовать.
Ну, Вы же не ответили на вопросы:
https://glav.su/foru…age4741956
Цитата: лателеннолоппа от 03.02.2018 15:14:41
Верный. Если, конечно перед этим не пялиться в упор на Солнце без светофильтра. Вообще такое ощущение, что Вы всю жизнь сидите в бункере и на природе не бываете. Сколько раз я лично замечал - за городом, даже после взгляда на яркий уличный фонарь(находясь непосредственно под фонарём) можно увидеть звёзды почти мгновенно, только переведя взгляд (я про ночное время) или закрыв ладонью фонарь. Даже после зайчика от сварки , пойманного случайно, зрение восстанавливается за 20-30 секунд. Но по вашему - нужно полдня высиживать в тени безвоздушного пространства. Бгг.
Цитата: лателеннолоппа от 03.02.2018 15:59:19
Вы, извините, из обывателей (читай - посетителей форума) делаете совсем дебилов. Ладно Вы сидите безвылазно за клавой, но большая часть людей не вчера родились.
---
Вот, как пример кто кого делает, скажите пожалуйста:
1) во сколько раз Солнце ярче уличного фонаря (примерно хотя бы)
2) освещает ли Ваш фонарь грунт или нет, и если освещает то с какой яркостью (фонарь
3) На сколько яркость грунта от фонаря слабее по яркости, чем освещенный Солнцем грунт на Луне.
4) можете ли вы закрыться от грунта рукой или нет
5) учитываете ли, что у астронавтов "иллюминатор" в виде прозрачного колпака шлема или нет.
Просто интересно, действительно...
Неделя прошла.
И о чем говорить с Вами то?
ЦитатаЦитата: лателеннолоппа от 10.02.2018 14:27:46
Им нечего сказать. Включая г-на Сеню, который не только покрывает юбиляров, но и снимает минусы с постов техников. Афёра продолжается, так или иначе, продолжайте . господа, продолжайте лицедействовать.
Клиника детектед.
Отредактировано: normalized_ - 10 фев 2018 14:29:04
Москва
Карма: +90.60
Регистрация: 07.06.2016
Сообщений: 5,219
Читатели: 17
Регистрация: 07.06.2016
Сообщений: 5,219
Читатели: 17
Цитата: лателеннолоппа от 10.02.2018 15:46:30Примерно - во сколько фонарь ближе Солнца
То есть по логике опровергающих полеты, чем ближе фонарь, тем фонарь слабее по яркости чем Солнце.
Оригинально.
Подумайте еще раз.
Цитата: лателеннолоппа от 10.02.2018 15:46:30Освещает, вполне, как днём
Различие освещённости не большое (не путать с интенсивностью)
Да, если рука вплотную к лицу.
У них под "колпаком" есть источники света? Нет? Тогда не учитываем.
Подумайте еще раз, причем начиная с первого вопроса.
Отредактировано: normalized_ - 10 фев 2018 18:34:02
Москва
Карма: +90.60
Регистрация: 07.06.2016
Сообщений: 5,219
Читатели: 17
Регистрация: 07.06.2016
Сообщений: 5,219
Читатели: 17
Цитата: лателеннолоппа от 10.02.2018 16:31:41Я ничего не должен доказывать. В моём лице вы видите рядового обывателя. не обременённого поисками доказательств, но периодически почитывающего баталии и споры. Я могу ошибаться, не так понимать, делать не верные выводы, но могу и просто - читать и не спорить. И как следствие общения других делать свои выводы. На данном этапе сторонники "заговора" выигрывают и мнение рядовых обывателей сводится к "американцы на Луну не летали". Как вам , защитникам, ни прискорбно, но это так. Особенно этот факт основывается на вашем. защитников, зубоскальстве и напыщенном диалоге. Ваш ЧСВ не доказательство, а лишь имхо.
Да, Вы и тут ошибаетесь.
Сейчас на ветке:
2,
Модераторов: 0,
Пользователей: 0,
Гостей: 0,
Ботов: 2