Понемножку обо всем
238,363
4,060

66 лет
Карма: +14.72
Регистрация: 16.11.2008
Сообщений: 4,046
Читатели: 4
Регистрация: 16.11.2008
Сообщений: 4,046
Читатели: 4

Тем не менее, с тех пор, как Петр Великий был царем, российские лидеры одержимы своей западной периферией. Однако несправедливое российское вторжение в Украину вынуждает изменить структуру российской политики. Будучи закрытой для Запада, вместо того, чтобы признать свою ошибку во вторжении на Украину, режим Путина поворачивается на Восток.
Это то, что и неоевразийцы, и силовики давно одобряют. У российской элиты сегодня больше нет выбора. Они должны отвернуться от Запада или быть уничтожены западными санкциями и усилением военных действий.
Таким образом, Россия становится азиатской страной – исполняя давно отложенные мечты царя Александра III, который построил Транссибирскую железную дорогу, связывающую более развитую “европейскую” сторону России с “Диким Востоком” России вдоль слаборазвитого тихоокеанского побережья.
Вместо того, чтобы сдаться подавляющему экономическому и политическому давлению, которому Запад подвергает русских; вместо того, чтобы свергнуть потенциального царя Владимира Путина, русские становятся все более пропутинскими. Они входят в классическую российскую модель сопротивления страшному аутсайдеру любой ценой – даже если это означает усиление власти страшного диктатора у себя дома.
Пути назад нет
Для тех западных элит, которые ошибочно полагают, что нынешнему противостоянию с Россией (которое закончится концом правления Путина и либо демократизацией России, либо распадом унитарного российского государства) близок конец, будьте готовы к тому, что окажетесь неправы.
Поэтому необходимо признать, что возврата к тому, как обстояли дела между Западом и Россией до 2022 года, нет. Москва достигла точки невозврата. То же самое происходит и с Западным альянсом.
Несмотря на все большие надежды, которые были в 2017-18 годах на то, чтобы перевернуть Россию, чтобы использовать ее против Китая, эти короткие дни надежды закончились. Лидеры Вашингтона, как демократы, так и республиканцы, должны принять новую болезненную реальность Евразии, в которой все больше объединяются Россия и китайская антиамериканская ось автократов.
Стратегии теперь должны быть разработаны соответствующим образом – и эти стратегии должны признать, что отныне на проецирование американской мощи в Евразию будут наложены реальные и серьезные ограничения.
Как однажды размышлял великий русский поэт Александр Блок в своем стихотворении
Скифы
Мильоны — вас. Нас — тьмы, и тьмы, и тьмы.
Попробуйте, сразитесь с нами!
Да, скифы — мы! Да, азиаты — мы,
С раскосыми и жадными очами!
Для вас — века, для нас — единый час.
Мы, как послушные холопы,
Держали щит меж двух враждебных рас
Монголов и Европы!
Века, века ваш старый горн ковал
И заглушал грома, лавины,
И дикой сказкой был для вас провал
И Лиссабона, и Мессины!
Вы сотни лет глядели на Восток
Копя и плавя наши перлы,
И вы, глумясь, считали только срок,
Когда наставить пушек жерла!
Вот — срок настал. Крылами бьет беда,
И каждый день обиды множит,
И день придет — не будет и следа
От ваших Пестумов, быть может!
О, старый мир! Пока ты не погиб,
Пока томишься мукой сладкой,
Остановись, премудрый, как Эдип,
Пред Сфинксом с древнею загадкой!
Россия — Сфинкс. Ликуя и скорбя,
И обливаясь черной кровью,
Она глядит, глядит, глядит в тебя
И с ненавистью, и с любовью!..
Да, так любить, как любит наша кровь,
Никто из вас давно не любит!
Забыли вы, что в мире есть любовь,
Которая и жжет, и губит!
Мы любим все — и жар холодных числ,
И дар божественных видений,
Нам внятно всё — и острый галльский смысл,
И сумрачный германский гений…
Мы помним всё — парижских улиц ад,
И венецьянские прохлады,
Лимонных рощ далекий аромат,
И Кельна дымные громады…
Мы любим плоть — и вкус ее, и цвет,
И душный, смертный плоти запах…
Виновны ль мы, коль хрустнет ваш скелет
В тяжелых, нежных наших лапах?
Привыкли мы, хватая под уздцы
Играющих коней ретивых,
Ломать коням тяжелые крестцы,
И усмирять рабынь строптивых…
Придите к нам! От ужасов войны
Придите в мирные обьятья!
Пока не поздно — старый меч в ножны,
Товарищи! Мы станем — братья!
А если нет — нам нечего терять,
И нам доступно вероломство!
Века, века вас будет проклинать
Больное позднее потомство!
Мы широко по дебрям и лесам
Перед Европою пригожей
Расступимся! Мы обернемся к вам
Своею азиатской рожей!
Идите все, идите на Урал!
Мы очищаем место бою
Стальных машин, где дышит интеграл,
С монгольской дикою ордою!
Но сами мы — отныне вам не щит,
Отныне в бой не вступим сами,
Мы поглядим, как смертный бой кипит,
Своими узкими глазами.
Не сдвинемся, когда свирепый гунн
В карманах трупов будет шарить,
Жечь города, и в церковь гнать табун,
И мясо белых братьев жарить!..
В последний раз — опомнись, старый мир!
На братский пир труда и мира,
В последний раз на светлый братский пир
Сзывает варварская лира!
Теперь американским лидерам придется смириться с печальным фактом, что Россия становится азиатской нацией ... и это, вероятно, положит конец мировой гегемонии Америки в нашей жизни, поскольку она лишает Америку легкого доступа к Евразии.
Аналитик составяющий свое заключение по неполным данным подобен игроку ставящему на число рулетки.
Взгляды отдельных авторов не обязательно отражают мою точку зрения
Гиперссылка на оригинальный материал находится в заголовке каждой статьи
Взгляды отдельных авторов не обязательно отражают мою точку зрения
Гиперссылка на оригинальный материал находится в заголовке каждой статьи
Карма: +0.03
Регистрация: 14.04.2021
Сообщений: 255
Читатели: 3
Регистрация: 14.04.2021
Сообщений: 255
Читатели: 3
Думаю, Донбасс и остальной юго-восток это уже несколько разные истории. ЛДНР войдут в состав России не позднее осени следующего года (под выборы), а остальные области лет 10-15 будут вариться либо народными республиками, либо Новороссией (но, скорее, первый вариант), разумеется под российским контролем. Через 10-15 лет процессов раззомбирования и интеграции с Россией, войдут в состав

65 лет
Карма: +0.10
Регистрация: 17.10.2008
Сообщений: 71
Читатели: 0
Регистрация: 17.10.2008
Сообщений: 71
Читатели: 0
Цитата: Prometeus от 27.04.2022 23:20:16Думаю, Донбасс и остальной юго-восток это уже несколько разные истории. ЛДНР войдут в состав России не позднее осени следующего года (под выборы), а остальные области лет 10-15 будут вариться либо народными республиками, либо Новороссией (но, скорее, первый вариант), разумеется под российским контролем. Через 10-15 лет процессов раззомбирования и интеграции с Россией, войдут в состав
Да и что-то я сомневаюсь, что на нарисованной диспозиции Россия остановится. Да, то, что нарисовано, заявлено как "второй этап спецоперации" - но кто сказал, что второй этап будет последним?
66 лет
Карма: +14.72
Регистрация: 16.11.2008
Сообщений: 4,046
Читатели: 4
Регистрация: 16.11.2008
Сообщений: 4,046
Читатели: 4
Вот главная причина, почему Россия должна полностью нейтрализовать Украину!
stateofthenation
27 апреля 2022 года

Россия была вынуждена начать свою “специальную военную операцию” в Украине, чтобы прекратить бушующую
биологическую войну, которую ведет биотеррористическая группа США-Великобритания-НАТО-УКРАИНА
— из своего секретного подпольного оперативного штаба, расположенного на
металлургическом комбинате "Азовсталь" в Мариуполе, Украина —
против народа Донбасса и западной России.
Вот почему Россия была вынуждена вторгнуться на Украину.
Эпическая битва за Мариуполь действительно касалась российской войны с спонсируемыми Пентагоном лабораториями биологического оружия, скрытыми в недрах сталелитейного завода "Азовсталь", а также многими другими до сих пор секретными биолабораториями, разбросанными по всей стране.
На сегодняшний день российские военные закрыли более 30 лабораторий биологического оружия по всей Украине. Однако главная лаборатория биологического оружия, систематически используемая для проведения будущих биотеррористических операций на Донбассе и западе России, стратегически расположена в Мариуполе на массивном комплексе "Азовсталь".
КЛЮЧЕВОЙ МОМЕНТ: Город Мариуполь расположен менее чем в 40 милях от российской границы, поэтому "Азовсталь" была выбрана для размещения одной из крупнейших лабораторий биологического оружия в мире. Мало того, что она базировалась прямо на Донбассе, но и "Азовсталь" была ближайшей биолабораторией, из которой можно было начать био-атаки против России. Смотрите: Российские военные разоблачили мощную лабораторию биологического оружия на МК "Азовсталь" в Мариуполе (видео)
Вот почему Россия так решительно настроена не взрывать "Авозсталь" и даже не нейтрализовать 1000 с лишним нацистов "Азова", скрывающихся там за живыми щитами — невинными украинскими гражданами. В частности, женщин и детей, вероятно, загнали на растянувшийся завод "Азовсталь" в качестве оборонительной стратегии против тотальной российской атаки. Но Россия действительно хочет и готова защищать военных лидеров США и НАТО, агентов западной разведки, офицеров ВСУ и украинских солдат, спрятавшихся в Азовстали, особенно тех, кто причастен к биотеррористическим операциям.
Путин точно знает, чем занимались биолаборатории "Азовстали". Ему также нужно сохранить доказательства, чтобы он мог показать всему миру, что биотеррористическая группа США-Великобритании-UA-НАТО планировала развязать как на Донбассе, так и в России.
Именно поэтому нацистам "Азова" дали такую свободу действий, чтобы терроризировать жителей Мариуполя. Они действовали по приказу своего командования НАТО, хозяев Пентагона и ЦРУ, чтобы установить абсолютный контроль над местом преступления биотеррора Азовстали. Не поэтому ли этих закоренелых неонацистов называют полком "Азов" и батальоном "Азов" (как на "Азовстали")? Эти закаленные в боях наемники были отправлены туда, чтобы обеспечить жестокие оборонительные и защитные услуги для англо-американских биотеррористических операций.
Что должен был сделать Кремль?
Позволить этой биотеррористической группе продолжать свой медленный геноцид граждан Донбасса?! Смотрите: НЕОПРОВЕРЖИМЫЕ ДОКАЗАТЕЛЬСТВА того, что азовские неонацисты Зеленского совершают геноцид против граждан Украины (видео)
Путин не только нанес первый и сильный удар, чтобы прекратить продолжающийся геноцид и будущую биологическую войну, он также неоднократно говорил мировому сообществу наций о цели российской “специальной военной операции”.
Мужественное решение Путина и др. вторжение, безусловно, было результатом широкого коллективного соглашения всего кремлевского руководства. В конце концов, Москва находится всего в 280 милях от украинской границы, так что они знали, что сталкиваются с ужасными экзистенциальными угрозами высшего порядка от военной экспансии НАТО и, в частности, образуют гораздо более опасную группу биотерроров.
Чрезвычайно агрессивные шаги и маневры НАТО только подтвердили худшие опасения Путина, как и несколько попыток расширить членство в НАТО, чтобы еще больше окружить Россию. Однако именно оперативное раскрытие украинских лабораторий биологического оружия действительно доказало правоту Путина в его миссии закрыть все геноцидальное предприятие — НАВСЕГДА!
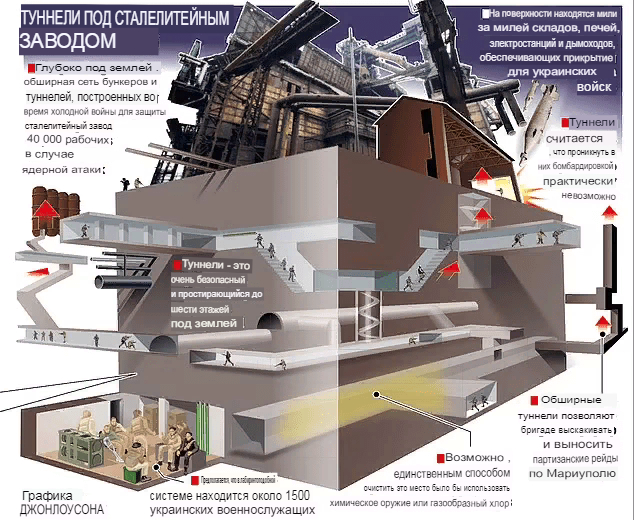
ИТОГ: у России не было выбора, кроме как вторгнуться в Украину, чтобы провести несколько “специальных военных операций” для защиты своего суверенитета и защиты своих граждан.
Не только это, но и “вмешательство России в Украину [СОВЕРШЕННО] законно по международному праву “.
stateofthenation
27 апреля 2022 года
“Специальная военная операция” России
в Украине - это МОРАЛЬНЫЙ ИМПЕРАТИВ
в Украине - это МОРАЛЬНЫЙ ИМПЕРАТИВ
Металлургический комбинат "Азовсталь" в Мариуполе, Украина, под атакой российских военных
ОПЕРАЦИЯ “АЗОВСТАЛЬ
” Путинская "Специальная военная
операция" по защите России и
разоблачению глобальной биологической войны
против человечества
” Путинская "Специальная военная
операция" по защите России и
разоблачению глобальной биологической войны
против человечества
Россия была вынуждена начать свою “специальную военную операцию” в Украине, чтобы прекратить бушующую
биологическую войну, которую ведет биотеррористическая группа США-Великобритания-НАТО-УКРАИНА
— из своего секретного подпольного оперативного штаба, расположенного на
металлургическом комбинате "Азовсталь" в Мариуполе, Украина —
против народа Донбасса и западной России.
Вот почему Россия была вынуждена вторгнуться на Украину.
Эпическая битва за Мариуполь действительно касалась российской войны с спонсируемыми Пентагоном лабораториями биологического оружия, скрытыми в недрах сталелитейного завода "Азовсталь", а также многими другими до сих пор секретными биолабораториями, разбросанными по всей стране.
На сегодняшний день российские военные закрыли более 30 лабораторий биологического оружия по всей Украине. Однако главная лаборатория биологического оружия, систематически используемая для проведения будущих биотеррористических операций на Донбассе и западе России, стратегически расположена в Мариуполе на массивном комплексе "Азовсталь".
КЛЮЧЕВОЙ МОМЕНТ: Город Мариуполь расположен менее чем в 40 милях от российской границы, поэтому "Азовсталь" была выбрана для размещения одной из крупнейших лабораторий биологического оружия в мире. Мало того, что она базировалась прямо на Донбассе, но и "Азовсталь" была ближайшей биолабораторией, из которой можно было начать био-атаки против России. Смотрите: Российские военные разоблачили мощную лабораторию биологического оружия на МК "Азовсталь" в Мариуполе (видео)
Вот почему Россия так решительно настроена не взрывать "Авозсталь" и даже не нейтрализовать 1000 с лишним нацистов "Азова", скрывающихся там за живыми щитами — невинными украинскими гражданами. В частности, женщин и детей, вероятно, загнали на растянувшийся завод "Азовсталь" в качестве оборонительной стратегии против тотальной российской атаки. Но Россия действительно хочет и готова защищать военных лидеров США и НАТО, агентов западной разведки, офицеров ВСУ и украинских солдат, спрятавшихся в Азовстали, особенно тех, кто причастен к биотеррористическим операциям.
Путин точно знает, чем занимались биолаборатории "Азовстали". Ему также нужно сохранить доказательства, чтобы он мог показать всему миру, что биотеррористическая группа США-Великобритании-UA-НАТО планировала развязать как на Донбассе, так и в России.
Именно поэтому нацистам "Азова" дали такую свободу действий, чтобы терроризировать жителей Мариуполя. Они действовали по приказу своего командования НАТО, хозяев Пентагона и ЦРУ, чтобы установить абсолютный контроль над местом преступления биотеррора Азовстали. Не поэтому ли этих закоренелых неонацистов называют полком "Азов" и батальоном "Азов" (как на "Азовстали")? Эти закаленные в боях наемники были отправлены туда, чтобы обеспечить жестокие оборонительные и защитные услуги для англо-американских биотеррористических операций.
Что должен был сделать Кремль?
Позволить этой биотеррористической группе продолжать свой медленный геноцид граждан Донбасса?! Смотрите: НЕОПРОВЕРЖИМЫЕ ДОКАЗАТЕЛЬСТВА того, что азовские неонацисты Зеленского совершают геноцид против граждан Украины (видео)
Путин не только нанес первый и сильный удар, чтобы прекратить продолжающийся геноцид и будущую биологическую войну, он также неоднократно говорил мировому сообществу наций о цели российской “специальной военной операции”.
Любой президент или премьер-министр на планете Земля был бы полностью оправдан
в принятии тех же военных мер, чтобы остановить
геноцид в процессе.
в принятии тех же военных мер, чтобы остановить
геноцид в процессе.
Мужественное решение Путина и др. вторжение, безусловно, было результатом широкого коллективного соглашения всего кремлевского руководства. В конце концов, Москва находится всего в 280 милях от украинской границы, так что они знали, что сталкиваются с ужасными экзистенциальными угрозами высшего порядка от военной экспансии НАТО и, в частности, образуют гораздо более опасную группу биотерроров.
Чрезвычайно агрессивные шаги и маневры НАТО только подтвердили худшие опасения Путина, как и несколько попыток расширить членство в НАТО, чтобы еще больше окружить Россию. Однако именно оперативное раскрытие украинских лабораторий биологического оружия действительно доказало правоту Путина в его миссии закрыть все геноцидальное предприятие — НАВСЕГДА!
Под сталелитейным комплексом "Азовстали" построена обширная туннельная система и лабораторный комплекс биологического оружия.
ИТОГ: у России не было выбора, кроме как вторгнуться в Украину, чтобы провести несколько “специальных военных операций” для защиты своего суверенитета и защиты своих граждан.
Не только это, но и “вмешательство России в Украину [СОВЕРШЕННО] законно по международному праву “.
Аналитик составяющий свое заключение по неполным данным подобен игроку ставящему на число рулетки.
Взгляды отдельных авторов не обязательно отражают мою точку зрения
Гиперссылка на оригинальный материал находится в заголовке каждой статьи
Взгляды отдельных авторов не обязательно отражают мою точку зрения
Гиперссылка на оригинальный материал находится в заголовке каждой статьи
63 года
Карма: -0.11
Регистрация: 13.03.2022
Сообщений: 158
Читатели: 0
Регистрация: 13.03.2022
Сообщений: 158
Читатели: 0
Цитата: Хранитель Храма от 26.04.2022 11:01:41Теперь мы знаем, что Олаф Шольц лично вмешался, чтобы заблокировать поставку тяжелого вооружения в Украину. В защиту своих действий он заявил, что поставки тяжелого вооружения будут истолкованы Россией как акт войны. Он специально упомянул ядерную войну.
Склоняюсь к варианту 1, что бизнес элиты Германии будут стараться сближаться с Россией.
66 лет
Карма: +14.72
Регистрация: 16.11.2008
Сообщений: 4,046
Читатели: 4
Регистрация: 16.11.2008
Сообщений: 4,046
Читатели: 4
Цитата: Никодим от 28.04.2022 11:31:17Склоняюсь к варианту 1, что бизнес элиты Германии будут стараться сближаться с Россией.
мне кажется, что для них сближение с Россией это вопрос выживания, но их деньги контролируют Штаты и аффилированные с ними европейские структуры... и в конечном итоге все решения они примут в тот момент, когда придет понимание, что их деньги уже давно не их деньги, и с одной стороны можно попробовать роль марионетки на американских веревочках, или отправляться в свободное плавание, опираясь на Россию, но с большими трудностями...
Аналитик составяющий свое заключение по неполным данным подобен игроку ставящему на число рулетки.
Взгляды отдельных авторов не обязательно отражают мою точку зрения
Гиперссылка на оригинальный материал находится в заголовке каждой статьи
Взгляды отдельных авторов не обязательно отражают мою точку зрения
Гиперссылка на оригинальный материал находится в заголовке каждой статьи
Карма: +21.40
Регистрация: 27.05.2021
Сообщений: 2,170
Читатели: 1
Регистрация: 27.05.2021
Сообщений: 2,170
Читатели: 1
Цитата: Хранитель Храма от 28.04.2022 18:03:58мне кажется, что для них сближение с Россией это вопрос выживания, но их деньги контролируют Штаты и аффилированные с ними европейские структуры... и в конечном итоге все решения они примут в тот момент, когда придет понимание, что их деньги уже давно не их деньги, и с одной стороны можно попробовать роль марионетки на американских веревочках, или отправляться в свободное плавание, опираясь на Россию, но с большими трудностями...
Это в Вашей логике.
А какого фига они станут русскими?
Для них в том смысле, в котором Вы говорите Россия страшна отсутствием (несущественностью) денег.
В России очень тонкая прослойка протестантов.
63 года
Карма: -0.11
Регистрация: 13.03.2022
Сообщений: 158
Читатели: 0
Регистрация: 13.03.2022
Сообщений: 158
Читатели: 0
Цитата: Хранитель Храма от 28.04.2022 18:03:58мне кажется, что для них сближение с Россией это вопрос выживания, но их деньги контролируют Штаты и аффилированные с ними европейские структуры... и в конечном итоге все решения они примут в тот момент, когда придет понимание, что их деньги уже давно не их деньги, и с одной стороны можно попробовать роль марионетки на американских веревочках, или отправляться в свободное плавание, опираясь на Россию, но с большими трудностями...
совершенно верно. я придерживаюсь примерно такой же концепции. Тут писал, и тут...
https://glav.su/foru…age6445187
https://glav.su/foru…age6444875
https://glav.su/foru…age6444841
https://glav.su/foru…age6444825
https://glav.su/foru…age6444785
однако у многих понимание процессов на уровне игры Зарница.
P.S. с интересеом читаю ваши тексты. Если даже не вы их писали то все равно, по их публикациям виден курс и простите за тавтологию видение процессов
Вот например человек с кармой почти +5000 пишет как ребенок:...
....Новости из Германии уже не интересны. Разума и воли там нет, пусть дохнут. Невозможно помочь утопающему, если он сам не хочет выплыть (вроде ВВП).
https://glav.su/foru…age6449836
Отредактировано: Никодим - 28 апр 2022 20:13:47
66 лет
Карма: +14.72
Регистрация: 16.11.2008
Сообщений: 4,046
Читатели: 4
Регистрация: 16.11.2008
Сообщений: 4,046
Читатели: 4
Верить в науку? Плохие исследования больших данных
могут поколебать вашу веру
Гэри Смит
26 апреля 2022 г.

Кофе был очень популярен в Швеции в 17 веке, и к тому же был
незаконным. Король Густав III, который считал, что это яд медленнодействующий, и придумал
хитрый эксперимент, чтобы доказать это. Он смягчил приговор братьям-близнецам-
убийцам, ожидавшим обезглавливания, при одном условии: один брат должен был
выпивать три чашки кофе каждый день, а другой - три чашки чая. Ранняя смерть
любителя кофе докажет, что кофе был ядом.
Оказалось, что близнец, пьющий кофе, пережил любителя чая, но только в 1820-х
годах шведам наконец разрешили делать то, что они делали все это время - пить кофе,
много кофе.
Краеугольным камнем научной революции является настойчивое требование проверки
заявлений данными, в идеале - в случайном контролируемом испытании. Эксперимент
Густава примечателен тем, что он использовал однояйцевых близнецов мужского пола,
что устранило смешанные эффекты пола, возраста и генов. Самая вопиющая слабость
заключалась в том, что из такой небольшой выборки нельзя было получить ничего
статистически убедительного.
Сегодня проблема не в недостатке данных, а в другом. У нас слишком много данных, и
это подрывает доверие к науке.
Удача присуща случайным испытаниям. В медицинском исследовании некоторые
пациенты могут быть здоровее. В сельскохозяйственном исследовании некоторые
почвы могут быть более плодородными. В образовательном исследовании некоторые
студенты могут быть более мотивированы. Следовательно, исследователи
рассчитывают вероятность (р-значение) того, что результаты могут произойти случайно.
Низкое р-значение указывает на то, что результаты не могут быть легко объяснены
удачей розыгрыша.
Как низко? В 1920-х годах великий британский статистик Рональд Фишер сказал, что он
считает р-значения ниже 5% убедительными, и поэтому 5% стали препятствием для
«статистически значимого» сертификата, необходимого для публикации,
финансирования и известности.
Это не сложное препятствие. Предположим, что незадачливый исследователь
вычисляет корреляции между сотнями переменных, в блаженном неведении о том, что
все данные на самом деле являются случайными числами. В среднем одна из 20
корреляций будет статистически значимой, хотя каждая корреляция - не более чем
совпадение.
Настоящие исследователи не сопоставляют случайные числа, но слишком часто они
сопоставляют то, что по сути является случайно выбранными переменными. У этого
случайного поиска статистической значимости даже есть название: интеллектуальный
анализ данных. Как и в случае со случайными числами, корреляция между случайно
выбранными, не связанными между собой переменными имеет 5-процентный шанс
оказаться статистически значимой. Интеллектуальный анализ данных можно
дополнить, манипулируя, сокращая и иным образом искажая данные, чтобы получить
низкие р-значения.
Чтобы найти статистическую значимость, нужно просто внимательно присмотреться.
Таким образом, 5-процентный барьер имел извращенный эффект, побуждая
исследователей проводить больше тестов и сообщать о большем количестве
бессмысленных результатов.
Таким образом, глупые отношения публикуются в хороших журналах просто потому, что
результаты статистически значимы.
Студенты лучше справляются с тестом на запоминание, если они готовятся к
тесту после его прохождения (Журнал психологии личности и социальной психологии).
Американцы японского происхождения подвержены сердечным приступам в
четвертый день месяца (Британский медицинский журнал).
Цены на биткойны можно предсказать на основе доходности акций в производстве
картона, контейнеров и коробок (Национальное бюро экономических
исследований).
Пожилые китаянки могут отложить свою смерть до празднования Праздника
Урожайной Луны (Журнал Американской медицинской ассоциации).
Женщины, которые ежедневно едят сухие завтраки, чаще рожают мальчиков
(Труды Королевского общества).
Люди могут использовать силовые позы, чтобы увеличить уровень гормона
доминирования тестостерона и снизить уровень гормона стресса кортизола
(психологическая наука).
Ураганы более смертоносны, если у них женские имена (Материалы Национальнои
Академии наук).
Инвесторы могут получить 23% годовой доход на рынке, основываясь на своих
решениях о покупке/продаже на количестве поисковых запросов в Гугле по слову
«долг" ( Научные отчеты ).
Эти ныне дискредитированные исследования - верхушка статистического айсберга,
известного как кризис репликации.
Команда под руководством Джона Иоаннидиса рассмотрела попытки воспроизвести 34
уважаемых медицинских исследования и обнаружила, что только 20 из них были
подтверждены. Проект воспроизводимости попытался воспроизвести 97 исследований,
опубликованных в ведущих журналах по психологии, и подтвердил только 35. Проект
репликации экспериментальной экономики попытался воспроизвести 18
экспериментальных исследований, опубликованных в ведущих экономических
журналах, и подтвердил только 11.
Я написал сатирическую статью, призванную продемонстрировать всю глупость
интеллектуального анализа данных. Я просмотрел объемные твиты Дональда Трампа и
обнаружил статистически значимые корреляции между: написанным Трампом в Твиттере
слова «президент» и индексом S&Р 500 два дня спустя; написанным Трампом в Твиттере слова
«когда-либо» и температурой в Москве четыре дня спустя; написанным Трампом в Твиттере
слова «еще» и ценой на чай в Китае четыре дня спустя; и написанным Трампом в Твиттере слова
«демократ» и несколькими случайными числами, которые я сгенерировал.
Я пришел к выводу - иронично, как только мог, - что нашел «убедительные
доказательства ценности использования алгоритмов интеллектуального анализа
данных для обнаружения статистически убедительных, ранее неизвестных корреляций,
которые можно использовать для создания надежных прогнозов».
Я наивно полагал, что читатели поймут смысл этой шутки ботаников: большие наборы
данных можно легко извлечь и подвергнуть пыткам, чтобы выявить совершенно
бесполезные закономерности. Я отправил статью в академический журнал, и
комментарии рецензента прекрасно демонстрируют, насколько глубоко укоренилось
представление о том, что статистическая значимость важнее здравого смысла: «Статья
в целом хорошо написана и структурирована. Это интересное исследование, и авторы
собрали уникальные наборы данных, используя передовую методологию».
Заманчиво полагать, что больше данных означает больше знаний. Однако
стремительный рост количества вещей, которые измеряются и регистрируются,
невероятно увеличил количество случайных паттернов и фиктивных статистических
взаимосвязей, ожидающих, чтобы нас обмануть.
Если количество истинных взаимосвязей, которые еще предстоит открыть, ограничено,
а число случайных закономерностей растет экспоненциально по мере накопления все
новых и новых данных, то вероятность того, что случайно обнаруженная
закономерность реальна, неизбежно приближается к нулю.
Проблема сегодня не в том, что у нас слишком мало данных, а в том, что у нас их
слишком много, что соблазняет исследователей рыться в них в поисках
закономерностей, которые легко найти, которые могут быть случайными и вряд ли
будут полезными.
могут поколебать вашу веру
Гэри Смит
26 апреля 2022 г.
Кофе был очень популярен в Швеции в 17 веке, и к тому же был
незаконным. Король Густав III, который считал, что это яд медленнодействующий, и придумал
хитрый эксперимент, чтобы доказать это. Он смягчил приговор братьям-близнецам-
убийцам, ожидавшим обезглавливания, при одном условии: один брат должен был
выпивать три чашки кофе каждый день, а другой - три чашки чая. Ранняя смерть
любителя кофе докажет, что кофе был ядом.
Оказалось, что близнец, пьющий кофе, пережил любителя чая, но только в 1820-х
годах шведам наконец разрешили делать то, что они делали все это время - пить кофе,
много кофе.
Краеугольным камнем научной революции является настойчивое требование проверки
заявлений данными, в идеале - в случайном контролируемом испытании. Эксперимент
Густава примечателен тем, что он использовал однояйцевых близнецов мужского пола,
что устранило смешанные эффекты пола, возраста и генов. Самая вопиющая слабость
заключалась в том, что из такой небольшой выборки нельзя было получить ничего
статистически убедительного.
Сегодня проблема не в недостатке данных, а в другом. У нас слишком много данных, и
это подрывает доверие к науке.
Удача присуща случайным испытаниям. В медицинском исследовании некоторые
пациенты могут быть здоровее. В сельскохозяйственном исследовании некоторые
почвы могут быть более плодородными. В образовательном исследовании некоторые
студенты могут быть более мотивированы. Следовательно, исследователи
рассчитывают вероятность (р-значение) того, что результаты могут произойти случайно.
Низкое р-значение указывает на то, что результаты не могут быть легко объяснены
удачей розыгрыша.
Как низко? В 1920-х годах великий британский статистик Рональд Фишер сказал, что он
считает р-значения ниже 5% убедительными, и поэтому 5% стали препятствием для
«статистически значимого» сертификата, необходимого для публикации,
финансирования и известности.
Это не сложное препятствие. Предположим, что незадачливый исследователь
вычисляет корреляции между сотнями переменных, в блаженном неведении о том, что
все данные на самом деле являются случайными числами. В среднем одна из 20
корреляций будет статистически значимой, хотя каждая корреляция - не более чем
совпадение.
Настоящие исследователи не сопоставляют случайные числа, но слишком часто они
сопоставляют то, что по сути является случайно выбранными переменными. У этого
случайного поиска статистической значимости даже есть название: интеллектуальный
анализ данных. Как и в случае со случайными числами, корреляция между случайно
выбранными, не связанными между собой переменными имеет 5-процентный шанс
оказаться статистически значимой. Интеллектуальный анализ данных можно
дополнить, манипулируя, сокращая и иным образом искажая данные, чтобы получить
низкие р-значения.
Чтобы найти статистическую значимость, нужно просто внимательно присмотреться.
Таким образом, 5-процентный барьер имел извращенный эффект, побуждая
исследователей проводить больше тестов и сообщать о большем количестве
бессмысленных результатов.
Таким образом, глупые отношения публикуются в хороших журналах просто потому, что
результаты статистически значимы.
Студенты лучше справляются с тестом на запоминание, если они готовятся к
тесту после его прохождения (Журнал психологии личности и социальной психологии).
Американцы японского происхождения подвержены сердечным приступам в
четвертый день месяца (Британский медицинский журнал).
Цены на биткойны можно предсказать на основе доходности акций в производстве
картона, контейнеров и коробок (Национальное бюро экономических
исследований).
Пожилые китаянки могут отложить свою смерть до празднования Праздника
Урожайной Луны (Журнал Американской медицинской ассоциации).
Женщины, которые ежедневно едят сухие завтраки, чаще рожают мальчиков
(Труды Королевского общества).
Люди могут использовать силовые позы, чтобы увеличить уровень гормона
доминирования тестостерона и снизить уровень гормона стресса кортизола
(психологическая наука).
Ураганы более смертоносны, если у них женские имена (Материалы Национальнои
Академии наук).
Инвесторы могут получить 23% годовой доход на рынке, основываясь на своих
решениях о покупке/продаже на количестве поисковых запросов в Гугле по слову
«долг" ( Научные отчеты ).
Эти ныне дискредитированные исследования - верхушка статистического айсберга,
известного как кризис репликации.
Команда под руководством Джона Иоаннидиса рассмотрела попытки воспроизвести 34
уважаемых медицинских исследования и обнаружила, что только 20 из них были
подтверждены. Проект воспроизводимости попытался воспроизвести 97 исследований,
опубликованных в ведущих журналах по психологии, и подтвердил только 35. Проект
репликации экспериментальной экономики попытался воспроизвести 18
экспериментальных исследований, опубликованных в ведущих экономических
журналах, и подтвердил только 11.
Я написал сатирическую статью, призванную продемонстрировать всю глупость
интеллектуального анализа данных. Я просмотрел объемные твиты Дональда Трампа и
обнаружил статистически значимые корреляции между: написанным Трампом в Твиттере
слова «президент» и индексом S&Р 500 два дня спустя; написанным Трампом в Твиттере слова
«когда-либо» и температурой в Москве четыре дня спустя; написанным Трампом в Твиттере
слова «еще» и ценой на чай в Китае четыре дня спустя; и написанным Трампом в Твиттере слова
«демократ» и несколькими случайными числами, которые я сгенерировал.
Я пришел к выводу - иронично, как только мог, - что нашел «убедительные
доказательства ценности использования алгоритмов интеллектуального анализа
данных для обнаружения статистически убедительных, ранее неизвестных корреляций,
которые можно использовать для создания надежных прогнозов».
Я наивно полагал, что читатели поймут смысл этой шутки ботаников: большие наборы
данных можно легко извлечь и подвергнуть пыткам, чтобы выявить совершенно
бесполезные закономерности. Я отправил статью в академический журнал, и
комментарии рецензента прекрасно демонстрируют, насколько глубоко укоренилось
представление о том, что статистическая значимость важнее здравого смысла: «Статья
в целом хорошо написана и структурирована. Это интересное исследование, и авторы
собрали уникальные наборы данных, используя передовую методологию».
Заманчиво полагать, что больше данных означает больше знаний. Однако
стремительный рост количества вещей, которые измеряются и регистрируются,
невероятно увеличил количество случайных паттернов и фиктивных статистических
взаимосвязей, ожидающих, чтобы нас обмануть.
Если количество истинных взаимосвязей, которые еще предстоит открыть, ограничено,
а число случайных закономерностей растет экспоненциально по мере накопления все
новых и новых данных, то вероятность того, что случайно обнаруженная
закономерность реальна, неизбежно приближается к нулю.
Проблема сегодня не в том, что у нас слишком мало данных, а в том, что у нас их
слишком много, что соблазняет исследователей рыться в них в поисках
закономерностей, которые легко найти, которые могут быть случайными и вряд ли
будут полезными.
Аналитик составяющий свое заключение по неполным данным подобен игроку ставящему на число рулетки.
Взгляды отдельных авторов не обязательно отражают мою точку зрения
Гиперссылка на оригинальный материал находится в заголовке каждой статьи
Взгляды отдельных авторов не обязательно отражают мою точку зрения
Гиперссылка на оригинальный материал находится в заголовке каждой статьи
Карма: 0.00
Регистрация: 29.04.2022
Сообщений: 1
Читатели: 0
Регистрация: 29.04.2022
Сообщений: 1
Читатели: 0
У меня вопросов нет, просто хочу оставить отзыв! Затянули меня как-то друзья на участие в форуме «Развитие студенческого самоуправления», шел туда с неохотой честно говоря, но потом ни капли не пожалел что поучаствовал! Это так круто, новые знакомства, полезная информация, смена обстановки!!Это не в общаге в компе сидеть))
66 лет
Карма: +14.72
Регистрация: 16.11.2008
Сообщений: 4,046
Читатели: 4
Регистрация: 16.11.2008
Сообщений: 4,046
Читатели: 4
Экономика велика. Средний класс безумен
Алана Семуэльс
28 апреля 2022

© Mark Steinmetz for TIME
Джефф Своуп почувствовал первый всплеск гнева, когда в феврале узнал, что его арендодатель повышает арендную плату за пустующую квартиру с двумя спальнями по соседству более чем на 30%, до 2075 долларов в месяц.
Хотя Своуп, 42-летний учитель, и его жена Аманда Грин, медсестра, зарабатывают 125 000 долларов в год, они не могли справиться с таким резким повышением арендной платы — не говоря уже о студенческих кредитах, оплате автомобиля, коммунальных платежах и всех других расходах, которые продолжали расти для семьи из трех человек. «Разочарование — это всегда была лягушка в кипящей воде. Я всегда чувствовал это, но на базовом уровне. Всегда что-то назревает», — говорит Своуп из своей скромной квартирки, где болванчики Atlanta Braves соревнуются с книгами за место на полках. «Мы посмотрели на повышение арендной платы и подумали, что это смешно. Я подумал: «Что за ???»
35-летняя Джен Дьюи-Осберн, живущая в пригороде Феникса, пришла в ярость, когда подсчитала, сколько она должна по студенческим кредитам: хотя она заняла 22 624 доллара и выплатила 34 225 долларов, она все еще должна 43 304 доллара. (Она спорит со своим кредитным специалистом, Navient, о том, как рассчитывались ее выплаты.) Она и ее муж знают, что им повезло больше, чем большинству — у обоих есть хорошая работа, — но они чувствуют себя настолько застрявшими в финансовом плане, что не могут себе представить, что возьмут на себя расходы по рождению детей. «Это просто моральное, физическое и эмоциональное истощение, — говорит она. «Нет правильного выбора; такое ощущение, что они все неправы».
Раздражение 26-летнего Омара Абдаллы достигло своего пика после того, как его 12-е предложение о доме провалилось, и он понял, насколько большей финансовой стабильности смогли добиться его родители, иммигранты в США, чем он и его жена. У них обоих есть дипломы хороших колледжей и многообещающие карьеры, но даже 90 000 долларов, которые они накопили на первый взнос, было недостаточно, когда продавец хотел гораздо больше, чем банк был готов ссудить за дом, который они хотели.
Родители Абдаллы, напротив, владеют двумя домами; родители его жены владеют четырьмя. «Вероятно, их дом приносил им больше денег, чем их работа», — говорит он. «У меня нет актива, в котором я мог бы спать, который приносит больше денег, чем мой ежедневный труд. Это та часть, которая просто ломает мне голову».
Семьи среднего класса в США десятилетиями топтались на месте из-за остановившегося роста доходов и роста цен, но безудержная инфляция, возникшая в результате пандемии, вызывает в их рядах не только волну разочарования. Сначала казалось, что пандемия может дать шанс наверстать упущенное; они сохранили свои рабочие места, поскольку сектор услуг уволил миллионы людей, их заработная плата начала расти более быстрыми темпами, поскольку компании изо всех сил пытались найти работников, и они начали откладывать больше, чем они делали в течение десятилетий. По данным Pew Research, около трети американцев со средним уровнем дохода почувствовали, что их финансовое положение улучшилось за год после начала пандемии, поскольку они находились на домашнем карантине, получая льготы по стимулирующим выплатам, налоговые льготы на детей и приостановку платежей федеральной студенческой ссуды.
«Наш доход якобы делает нас выше среднего класса, но это точно не похоже на это».
Но 18 месяцев спустя они все больше подозревают, что любое чувство финансовой безопасности было иллюзией. У них может быть больше денег в банке, но принадлежность к среднему классу в Америке зависит не только от того, сколько вы зарабатываете; речь идет о том, что вы можете купить на эти деньги. Некоторые люди измеряют это тем, есть ли у семьи второй холодильник в подвале или дерево во дворе, но Ричард Ривз, директор инициативы «Будущее среднего класса» в Брукингском институте, говорит, что действительно важно то, чувствуют ли люди, что они могут с комфортом позволить себе «три Н» — жилье, здравоохранение и высшее образование (housing, health care, and higher education).
Только за последний год цены на жилье подскочили на 20%, а стоимость всех товаров выросла на 8,5%. В этом году семьи платят на 3500 долларов больше за базовый набор товаров и услуг, за которыми следует индекс потребительских цен (ИПЦ), чем в прошлом году. Средний почасовой заработок, напротив, с поправкой на инфляцию снизился на 2,7%. Это давление привело к тому, что многие из тех, кто идентифицирует себя как средний класс, не могут позволить себе три «Н», особенно жилье. Согласно опросу потребителей Мичиганского университета, в марте настроения потребителей в США достигли самого низкого уровня с 2011 года, и больше домохозяйств заявили, что ожидают ухудшения своего финансового положения, чем когда-либо с мая 1980 года.
«Мантра была такой: работай усердно, плати взносы, и ты будешь вознагражден за это. Но стойки ворот продолжают отодвигать», — говорит Даниэль Барела, 36 лет, бортпроводник из Альбукерке, штат Нью-Мексико, который прекрасно знает, что к его возрасту у его отца был дом и четверо детей. В прошлом году Барела и его партнер заработали на двоих около 69 000 долларов, и ему кажется, что большую часть своей взрослой жизни он был зажат в финансовом плане. Он потерял работу во время Великой рецессии, а после того, как в 2008 году крупная компания, выпускающая кредитные карты, подняла его процентную ставку до 29,99%, ему пришлось объявить себя банкротом. «Независимо от того, какую работу я выполнял и сколько бы я ни работал, этого никогда не бывает достаточно, чтобы соответствовать требованиям для владения домом», — говорит он.
Даже если люди возраста Барелы, которые сегодня составляют большую часть среднего класса, зарабатывают больше денег, чем их родители, даже если у них есть высшее образование и выбор работы, даже если у них есть жилье, iPhone и телевизор с плоским экраном, многие теперь чувствуют, что, хотя они следовали всем рекомендациям американского общества, они каким-то образом оказались финансово неустойчивыми. «Предполагается, что наш доход делает нас выше среднего класса, но это не похоже на то», — говорит Своуп. «Если вы принадлежите к среднему классу, вы можете позволить себе веселье, а мы — нет».
TIME поговорил с десятками людей по всей стране , все доходы которых попадают в средние 60% доходов американцев, что Брукингс определяет как средний класс. Сегодня для семьи из трех человек это составляет от 42 500 до 166 900 долларов. Вот что мы услышали:
«Американская мечта» — это абсолютный кошмар, и сейчас я просто хочу уйти».
«Это действительно обескураживает. Я теряю надежду. Я не знаю, что делать».
«Мы сделали то, что должны были сделать, но мы просто слишком обременены расходами».
«Это самые большие деньги, которые я когда-либо зарабатывал, но я все еще не могу позволить себе купить дом».
«Я пустил здесь корни. Я не хочу, чтобы меня выгнали».
Многие упомянули об обиде на своих родителей или старших коллег, которые не понимают, почему это молодое поколение не имеет признаков среднего класса, таких как дом на одну семью или погашенный долг за колледж. «Бумеры могли буквально работать за минимальную заработную плату, они могли получать жизненный опыт — ездить в национальные парки или иметь детей и собственные дома. Для нас это просто невозможно», — говорит Джули Энн Нитч, государственный служащий в Остине, которая, когда в мае дом, который она снимает, будет выставлена на продажу, больше не сможет жить в округе, который она обслуживает.
У них есть точка зрения. Домовладение становилось все более неуловимым для каждого последующего поколения, поскольку цены на недвижимость опережали инфляцию. По данным Urban Institute, в 1980 году более 70% людей в возрасте от 35 до 44 лет владели домом, но к 2018 году менее 60% людей в этой возрастной группе купили жилье. Стремительный рост стоимости жилья, занимаемого владельцами, который к концу 2019 года достиг $29,3 трлн, создал разрыв, обогащая пожилых американцев, владеющих домами, и вытесняя более молодых, которые не могут позволить себе выйти на рынок.
«Может потребоваться некоторое время, чтобы экономическое тектоническое давление нарастало в достаточной степени, и сейчас вулкан извергается».
Миллениалы и молодые поколения достигли совершеннолетия в условиях худшей рецессии за последние десятилетия, вышли на рынок труда, где их заработная плата росла вяло, а затем пережили еще одну рецессию в начале пандемии. Несмотря на все это, расходы продолжали расти. Средний доход домохозяйства вырос всего на 9% с 2001 года, но плата за обучение в колледже и плата за него выросли на 64% за тот же период времени, а расходы на медицинское обслуживание из собственного кармана почти удвоились. Только половина всех детей, родившихся в 1980-х годах, выросли и зарабатывают больше, чем их родители, по сравнению с более чем 90% детей в 1940-х годах. По данным Bloomberg, как миллениалы, так и поколение X имеют меньший собственный капитал и больший долг, когда они достигают возраста 40 лет, чем бумеры в этом возрасте.
Их заботы важны для американской экономики в целом. Как сказал Джо Байден в 2019 году: «Когда средний класс преуспевает, все преуспевают. Богатые преуспевают, а у бедных есть свет, шанс. Они смотрят на это так: «Может быть, я — может быть, есть способ».
Если средний класс чувствует себя обделенным одной из самых сильных экономик за последние десятилетия, когда уровень безработицы находится на историческом минимуме, это серьезный признак того, что грядут социальные разногласия. Прямо сейчас нет ни Великой рецессии, ни технологического кризиса, ни краха сложных инвестиционных продуктов в сфере недвижимости, чтобы объяснить, почему дела идут плохо. На первый взгляд экономика выглядит оживленной. Но, подобно медленно готовящейся лягушке Своупа, многие работники со средним доходом понимают, что они в горячей воде и идут ко дну. «Этот вулкан не появился из ниоткуда, — говорит Ривз, директор Инициативы «Будущее среднего класса». «В какой-то степени мы наблюдаем такие долгосрочные сдвиги в экономике, как вялый рост заработной платы и нисходящая мобильность. Может потребоваться некоторое время, чтобы экономическое тектоническое давление нарастало в достаточной степени, и сейчас вулкан извергается».
За последние несколько десятилетий стоимость всех трех «Н» резко возросла , но именно стоимость жилья — обычно самая крупная и важная статья расходов для любой семьи — в значительной степени подпитывает нынешнее недовольство. Цены на жилье неуклонно росли на протяжении десятилетий, за исключением падения с 2007 по 2009 год, но в прошлом году рост достиг апогея. Немногие места невосприимчивы; более чем в 80% городских районов США цены на жилье выросли не менее чем на 10%. В районе метро Атланты, где живут Своуп и Грин, средняя цена листинга составляет 400 000 долларов, что на 7,5% больше, чем в прошлом году. (Они думают, что могут позволить себе дом стоимостью 300 000 долларов.)
Рост цен вызван легионом сил, в том числе отставанием в строительстве после Великой рецессии, ростом краткосрочной аренды, спекуляциями институциональных инвесторов, владеющих растущей долей домов на одну семью, нехваткой строительных материалов, а также вопросы рабочей силы и цепочки поставок. Они усугубляются растущим спросом со стороны семей, желающих потратить сэкономленные деньги, бумеров, которые стареют на месте, а не рискуют жизнью в учреждении во время пандемии, и миллениалов, стремящихся создать семью.
Недавняя борьба за покупку домов хорошо задокументирована, но во многих местах арендаторы находятся в худшем положении, чем покупатели. Арендная плата выросла почти на 30% в некоторых штатах в 2021 году и, по прогнозам, вырастет в этом году. 37-летний Дэвид Робинсон родился и вырос в Финиксе, а сейчас живет со своей девушкой и тремя детьми в скромной квартире с тремя спальнями в Мэривейле, которую он считает бедной частью города. В сентябре их арендная плата выросла с 1200 долларов в месяц до 2200 долларов с учетом дополнительных сборов после того, как, по его словам, «какая-то управляющая компания из Вашингтона [штат]» купила здание. Его арендная плата теперь составляет около 50% его дохода в качестве инспектора коммунальных услуг.
«Тяжело что-то делать со своей семьей, — говорит он. «После покупки одежды, еды и [оплаты] других счетов, таких как электричество, вода и тому подобное, финансовая подушка становится очень тонкой. Я в значительной степени работаю, чтобы оплачивать чужие счета». Он скрещивает пальцы, чтобы их машины продержались чуть дольше, не говоря уже об их здоровье.
Аманда Грин, жена Джеффа Своупа, знает это чувство. Она должна 19 000 долларов за свою Toyota Corolla, на которую она понизила класс после того, как ее Jeep Cherokee неожиданно умер. И до того, как она вышла замуж за Джеффа и пошла на его программу медицинского страхования, страховка для нее и ее 7-летней дочери через ее работодателя стоила 1400 долларов в месяц. Грин покрывала только себя и платила из своего кармана за дочь. У нее заболевание, требующее тщательного обследования, и она все еще выплачивает тысячи долларов, которые не покрыла ее страховка.
Алана Семуэльс
28 апреля 2022
© Mark Steinmetz for TIME
Джефф Своуп почувствовал первый всплеск гнева, когда в феврале узнал, что его арендодатель повышает арендную плату за пустующую квартиру с двумя спальнями по соседству более чем на 30%, до 2075 долларов в месяц.
Хотя Своуп, 42-летний учитель, и его жена Аманда Грин, медсестра, зарабатывают 125 000 долларов в год, они не могли справиться с таким резким повышением арендной платы — не говоря уже о студенческих кредитах, оплате автомобиля, коммунальных платежах и всех других расходах, которые продолжали расти для семьи из трех человек. «Разочарование — это всегда была лягушка в кипящей воде. Я всегда чувствовал это, но на базовом уровне. Всегда что-то назревает», — говорит Своуп из своей скромной квартирки, где болванчики Atlanta Braves соревнуются с книгами за место на полках. «Мы посмотрели на повышение арендной платы и подумали, что это смешно. Я подумал: «Что за ???»
35-летняя Джен Дьюи-Осберн, живущая в пригороде Феникса, пришла в ярость, когда подсчитала, сколько она должна по студенческим кредитам: хотя она заняла 22 624 доллара и выплатила 34 225 долларов, она все еще должна 43 304 доллара. (Она спорит со своим кредитным специалистом, Navient, о том, как рассчитывались ее выплаты.) Она и ее муж знают, что им повезло больше, чем большинству — у обоих есть хорошая работа, — но они чувствуют себя настолько застрявшими в финансовом плане, что не могут себе представить, что возьмут на себя расходы по рождению детей. «Это просто моральное, физическое и эмоциональное истощение, — говорит она. «Нет правильного выбора; такое ощущение, что они все неправы».
Раздражение 26-летнего Омара Абдаллы достигло своего пика после того, как его 12-е предложение о доме провалилось, и он понял, насколько большей финансовой стабильности смогли добиться его родители, иммигранты в США, чем он и его жена. У них обоих есть дипломы хороших колледжей и многообещающие карьеры, но даже 90 000 долларов, которые они накопили на первый взнос, было недостаточно, когда продавец хотел гораздо больше, чем банк был готов ссудить за дом, который они хотели.
Родители Абдаллы, напротив, владеют двумя домами; родители его жены владеют четырьмя. «Вероятно, их дом приносил им больше денег, чем их работа», — говорит он. «У меня нет актива, в котором я мог бы спать, который приносит больше денег, чем мой ежедневный труд. Это та часть, которая просто ломает мне голову».
Семьи среднего класса в США десятилетиями топтались на месте из-за остановившегося роста доходов и роста цен, но безудержная инфляция, возникшая в результате пандемии, вызывает в их рядах не только волну разочарования. Сначала казалось, что пандемия может дать шанс наверстать упущенное; они сохранили свои рабочие места, поскольку сектор услуг уволил миллионы людей, их заработная плата начала расти более быстрыми темпами, поскольку компании изо всех сил пытались найти работников, и они начали откладывать больше, чем они делали в течение десятилетий. По данным Pew Research, около трети американцев со средним уровнем дохода почувствовали, что их финансовое положение улучшилось за год после начала пандемии, поскольку они находились на домашнем карантине, получая льготы по стимулирующим выплатам, налоговые льготы на детей и приостановку платежей федеральной студенческой ссуды.
«Наш доход якобы делает нас выше среднего класса, но это точно не похоже на это».
Но 18 месяцев спустя они все больше подозревают, что любое чувство финансовой безопасности было иллюзией. У них может быть больше денег в банке, но принадлежность к среднему классу в Америке зависит не только от того, сколько вы зарабатываете; речь идет о том, что вы можете купить на эти деньги. Некоторые люди измеряют это тем, есть ли у семьи второй холодильник в подвале или дерево во дворе, но Ричард Ривз, директор инициативы «Будущее среднего класса» в Брукингском институте, говорит, что действительно важно то, чувствуют ли люди, что они могут с комфортом позволить себе «три Н» — жилье, здравоохранение и высшее образование (housing, health care, and higher education).
Только за последний год цены на жилье подскочили на 20%, а стоимость всех товаров выросла на 8,5%. В этом году семьи платят на 3500 долларов больше за базовый набор товаров и услуг, за которыми следует индекс потребительских цен (ИПЦ), чем в прошлом году. Средний почасовой заработок, напротив, с поправкой на инфляцию снизился на 2,7%. Это давление привело к тому, что многие из тех, кто идентифицирует себя как средний класс, не могут позволить себе три «Н», особенно жилье. Согласно опросу потребителей Мичиганского университета, в марте настроения потребителей в США достигли самого низкого уровня с 2011 года, и больше домохозяйств заявили, что ожидают ухудшения своего финансового положения, чем когда-либо с мая 1980 года.
«Мантра была такой: работай усердно, плати взносы, и ты будешь вознагражден за это. Но стойки ворот продолжают отодвигать», — говорит Даниэль Барела, 36 лет, бортпроводник из Альбукерке, штат Нью-Мексико, который прекрасно знает, что к его возрасту у его отца был дом и четверо детей. В прошлом году Барела и его партнер заработали на двоих около 69 000 долларов, и ему кажется, что большую часть своей взрослой жизни он был зажат в финансовом плане. Он потерял работу во время Великой рецессии, а после того, как в 2008 году крупная компания, выпускающая кредитные карты, подняла его процентную ставку до 29,99%, ему пришлось объявить себя банкротом. «Независимо от того, какую работу я выполнял и сколько бы я ни работал, этого никогда не бывает достаточно, чтобы соответствовать требованиям для владения домом», — говорит он.
Даже если люди возраста Барелы, которые сегодня составляют большую часть среднего класса, зарабатывают больше денег, чем их родители, даже если у них есть высшее образование и выбор работы, даже если у них есть жилье, iPhone и телевизор с плоским экраном, многие теперь чувствуют, что, хотя они следовали всем рекомендациям американского общества, они каким-то образом оказались финансово неустойчивыми. «Предполагается, что наш доход делает нас выше среднего класса, но это не похоже на то», — говорит Своуп. «Если вы принадлежите к среднему классу, вы можете позволить себе веселье, а мы — нет».
TIME поговорил с десятками людей по всей стране , все доходы которых попадают в средние 60% доходов американцев, что Брукингс определяет как средний класс. Сегодня для семьи из трех человек это составляет от 42 500 до 166 900 долларов. Вот что мы услышали:
«Американская мечта» — это абсолютный кошмар, и сейчас я просто хочу уйти».
«Это действительно обескураживает. Я теряю надежду. Я не знаю, что делать».
«Мы сделали то, что должны были сделать, но мы просто слишком обременены расходами».
«Это самые большие деньги, которые я когда-либо зарабатывал, но я все еще не могу позволить себе купить дом».
«Я пустил здесь корни. Я не хочу, чтобы меня выгнали».
Многие упомянули об обиде на своих родителей или старших коллег, которые не понимают, почему это молодое поколение не имеет признаков среднего класса, таких как дом на одну семью или погашенный долг за колледж. «Бумеры могли буквально работать за минимальную заработную плату, они могли получать жизненный опыт — ездить в национальные парки или иметь детей и собственные дома. Для нас это просто невозможно», — говорит Джули Энн Нитч, государственный служащий в Остине, которая, когда в мае дом, который она снимает, будет выставлена на продажу, больше не сможет жить в округе, который она обслуживает.
У них есть точка зрения. Домовладение становилось все более неуловимым для каждого последующего поколения, поскольку цены на недвижимость опережали инфляцию. По данным Urban Institute, в 1980 году более 70% людей в возрасте от 35 до 44 лет владели домом, но к 2018 году менее 60% людей в этой возрастной группе купили жилье. Стремительный рост стоимости жилья, занимаемого владельцами, который к концу 2019 года достиг $29,3 трлн, создал разрыв, обогащая пожилых американцев, владеющих домами, и вытесняя более молодых, которые не могут позволить себе выйти на рынок.
«Может потребоваться некоторое время, чтобы экономическое тектоническое давление нарастало в достаточной степени, и сейчас вулкан извергается».
Миллениалы и молодые поколения достигли совершеннолетия в условиях худшей рецессии за последние десятилетия, вышли на рынок труда, где их заработная плата росла вяло, а затем пережили еще одну рецессию в начале пандемии. Несмотря на все это, расходы продолжали расти. Средний доход домохозяйства вырос всего на 9% с 2001 года, но плата за обучение в колледже и плата за него выросли на 64% за тот же период времени, а расходы на медицинское обслуживание из собственного кармана почти удвоились. Только половина всех детей, родившихся в 1980-х годах, выросли и зарабатывают больше, чем их родители, по сравнению с более чем 90% детей в 1940-х годах. По данным Bloomberg, как миллениалы, так и поколение X имеют меньший собственный капитал и больший долг, когда они достигают возраста 40 лет, чем бумеры в этом возрасте.
Их заботы важны для американской экономики в целом. Как сказал Джо Байден в 2019 году: «Когда средний класс преуспевает, все преуспевают. Богатые преуспевают, а у бедных есть свет, шанс. Они смотрят на это так: «Может быть, я — может быть, есть способ».
Если средний класс чувствует себя обделенным одной из самых сильных экономик за последние десятилетия, когда уровень безработицы находится на историческом минимуме, это серьезный признак того, что грядут социальные разногласия. Прямо сейчас нет ни Великой рецессии, ни технологического кризиса, ни краха сложных инвестиционных продуктов в сфере недвижимости, чтобы объяснить, почему дела идут плохо. На первый взгляд экономика выглядит оживленной. Но, подобно медленно готовящейся лягушке Своупа, многие работники со средним доходом понимают, что они в горячей воде и идут ко дну. «Этот вулкан не появился из ниоткуда, — говорит Ривз, директор Инициативы «Будущее среднего класса». «В какой-то степени мы наблюдаем такие долгосрочные сдвиги в экономике, как вялый рост заработной платы и нисходящая мобильность. Может потребоваться некоторое время, чтобы экономическое тектоническое давление нарастало в достаточной степени, и сейчас вулкан извергается».
За последние несколько десятилетий стоимость всех трех «Н» резко возросла , но именно стоимость жилья — обычно самая крупная и важная статья расходов для любой семьи — в значительной степени подпитывает нынешнее недовольство. Цены на жилье неуклонно росли на протяжении десятилетий, за исключением падения с 2007 по 2009 год, но в прошлом году рост достиг апогея. Немногие места невосприимчивы; более чем в 80% городских районов США цены на жилье выросли не менее чем на 10%. В районе метро Атланты, где живут Своуп и Грин, средняя цена листинга составляет 400 000 долларов, что на 7,5% больше, чем в прошлом году. (Они думают, что могут позволить себе дом стоимостью 300 000 долларов.)
Рост цен вызван легионом сил, в том числе отставанием в строительстве после Великой рецессии, ростом краткосрочной аренды, спекуляциями институциональных инвесторов, владеющих растущей долей домов на одну семью, нехваткой строительных материалов, а также вопросы рабочей силы и цепочки поставок. Они усугубляются растущим спросом со стороны семей, желающих потратить сэкономленные деньги, бумеров, которые стареют на месте, а не рискуют жизнью в учреждении во время пандемии, и миллениалов, стремящихся создать семью.
Недавняя борьба за покупку домов хорошо задокументирована, но во многих местах арендаторы находятся в худшем положении, чем покупатели. Арендная плата выросла почти на 30% в некоторых штатах в 2021 году и, по прогнозам, вырастет в этом году. 37-летний Дэвид Робинсон родился и вырос в Финиксе, а сейчас живет со своей девушкой и тремя детьми в скромной квартире с тремя спальнями в Мэривейле, которую он считает бедной частью города. В сентябре их арендная плата выросла с 1200 долларов в месяц до 2200 долларов с учетом дополнительных сборов после того, как, по его словам, «какая-то управляющая компания из Вашингтона [штат]» купила здание. Его арендная плата теперь составляет около 50% его дохода в качестве инспектора коммунальных услуг.
«Тяжело что-то делать со своей семьей, — говорит он. «После покупки одежды, еды и [оплаты] других счетов, таких как электричество, вода и тому подобное, финансовая подушка становится очень тонкой. Я в значительной степени работаю, чтобы оплачивать чужие счета». Он скрещивает пальцы, чтобы их машины продержались чуть дольше, не говоря уже об их здоровье.
Аманда Грин, жена Джеффа Своупа, знает это чувство. Она должна 19 000 долларов за свою Toyota Corolla, на которую она понизила класс после того, как ее Jeep Cherokee неожиданно умер. И до того, как она вышла замуж за Джеффа и пошла на его программу медицинского страхования, страховка для нее и ее 7-летней дочери через ее работодателя стоила 1400 долларов в месяц. Грин покрывала только себя и платила из своего кармана за дочь. У нее заболевание, требующее тщательного обследования, и она все еще выплачивает тысячи долларов, которые не покрыла ее страховка.
Аналитик составяющий свое заключение по неполным данным подобен игроку ставящему на число рулетки.
Взгляды отдельных авторов не обязательно отражают мою точку зрения
Гиперссылка на оригинальный материал находится в заголовке каждой статьи
Взгляды отдельных авторов не обязательно отражают мою точку зрения
Гиперссылка на оригинальный материал находится в заголовке каждой статьи
66 лет
Карма: +14.72
Регистрация: 16.11.2008
Сообщений: 4,046
Читатели: 4
Регистрация: 16.11.2008
Сообщений: 4,046
Читатели: 4
«Угроза номер один для американского конституционного правительства сегодня — это крах среднего класса».
За последние два десятилетия медицинские расходы, как правило, росли быстрее, чем инфляция, что было вызвано увеличением стоимости медицинского обслуживания и увеличением спроса на услуги из-за старения населения. Национальные расходы на здравоохранение на душу населения в 1980 году с поправкой на инфляцию составили 2968 долларов; к 2020 году это было в четыре раза больше. Пандемия усугубила проблемы, так как многие люди потеряли работу и страховку. Согласно опросу, проведенному Фондом Содружества, более половины взрослых, заразившихся COVID-19 или потерявших доход во время пандемии, также столкнулись с проблемами, связанными с медицинскими счетами.
Высшее образование, третье H, также неуклонно дорожало, поскольку стоимость обучения в колледже росла, а федеральное финансирование государственных университетов резко падало. По мере роста цен все больше студентов брали кредиты. Средний долг по студенческой ссуде в 2020 году составлял 36 635 долларов, что примерно вдвое больше, чем в 1990 году, с поправкой на инфляцию. Семьи десятилетиями борются за то, чтобы не отставать от выплат. Грин думала, что выделяет себя, когда поступила в частный колледж, чтобы получить степень медсестры. Теперь она должна кредита на 99 000 долларов, а две ее сестры, которые не учились в колледже, свободны от долгов.
Для многих выпускников колледжей пандемия принесла некоторое облегчение, когда Закон CARES приостановил выплаты по федеральным студенческим кредитам. Внезапно у людей появились деньги, чтобы оплачивать другие счета, и они увидели, какой будет жизнь без калечащих студенческих долгов. Грин смотрела приложение на своем телефоне, когда ее кредит остановился на 99 000 долларов — и остался там. Она боится, когда снова начнутся выплаты.
В целом, три «Н» — арендная плата, здравоохранение и ссуды на высшее образование — занимают растущую долю получаемой Своупом и Грином заработной платы. Добавьте предметы первой необходимости, такие как еда и коммунальные услуги, и у них будут месяцы, когда они будут выписывать чеки за аренду, не имея достаточно денег на своем текущем счете. (Swope получает зарплату ежемесячно.) Они не едят вне дома. Они переключились на общие продуктовые бренды. Хотя они оба работают полный рабочий день, Своуп рассматривает возможность подработки.
Некоторые экономисты утверждают, что бедственное положение среднего класса маскируется плохим бухгалтерским учетом. Юджин Людвиг, бывший контролер денежного обращения в администрации Клинтона, говорит, что индекс потребительских цен искажает реальную экономическую картину для американцев с низким и средним уровнем доходов, поскольку он учитывает стоимость необязательных предметов, таких как яхты, вторые дома и гостиничные номера. По его подсчетам, стоимость минимальных потребностей домохозяйства выросла на 64% с 2001 по 2020 год, что на 1,4% быстрее инфляции. В марте Институт совместного экономического процветания Людвига опубликовал отчет, в котором говорилось, что цены на жилье фактически выросли на 149% (ИПЦ оценил их на 54%), а расходы на медицинское обслуживание выросли на 157% (по сравнению с 90%).
«Мы обнаружили, что, хотя в 2001 году у людей, возможно, были лишь небольшие дискреционные расходы, к 2019 году для сравнения их не было во многих семьях, особенно в семьях с большим количеством детей», — говорит исполнительный директор Института Людвига Стефани Аллен. (По ее словам, с тех пор пандемия сделала отслеживание этих данных слишком ненадежным для оценки дискреционных расходов.)
Стресс и гнев, которые испытывают люди в возрасте от 30 до 40 лет, распространяются на их отношения с поколением их родителей. Сегодня семья в США, имеющая средний доход на домохозяйство, должна платить в шесть раз больше этого дохода, чтобы купить дом по средней цене. В 1980 году им пришлось бы платить вдвойне. Но многие бумеры, кажется, не очень сочувствуют затруднительному положению своих детей. Отец Джеффа Своупа смог содержать семью из трех человек на зарплату социального работника и купил дом в Сэнди-Спрингс, штат Джорджия, примерно за 50 000 долларов. Его мать продала его в прошлом году за 255 000 долларов, а тот покупатель продал его в марте на 30% дороже.
Своуп, с другой стороны, окончил колледж со степенью в области маркетинга в 2003 году и устроился продавать рекламу в «Желтых страницах». Когда этот бизнес исчез с распространением поисковых систем в Интернете, он работал официантом и получил второе высшее образование, чтобы преподавать. Он получил высшее образование в 2008 году в разгар Великой рецессии и зарабатывал себе на жизнь, работая ведущим викторин и занимая любые места преподавания, которые он мог найти.
До 2013 года он не устраивался на работу учителем начального уровня в государственной школе. Даже сейчас его дохода в 55 000 долларов недостаточно, чтобы прокормить семью. Он и Грин подали заявку на предварительное одобрение ипотеки, но не получили ответа. Он чувствует себя застрявшим. «Это похоже на то, что ты не взрослый, если у тебя нет дома», — говорит он. «Старшее поколение смотрит на вас свысока, потому что просто не понимает».
Одна из вещей, которую некоторым людям труднее понять, — это волновые эффекты структурных изменений, которые только начинались, когда они были моложе. Например, из-за упадка профсоюзов, длившегося несколько десятилетий, рабочим стало труднее вести переговоры о повышении заработной платы и пособий. Своуп не состоит в профсоюзе учителей, потому что в Джорджии запрещены коллективные переговоры для государственных педагогов, что является одной из причин, по которой средний учитель государственной школы зарабатывал в 2020–2021 учебном году на 5% меньше, чем в 1999–2000 годах, с поправкой на инфляцию. В Массачусетсе, штате с сильными профсоюзами учителей, средняя заработная плата учителя государственной школы за тот же период выросла на 19%.
По всей стране становится все труднее найти работу с медицинским обслуживанием и другими льготами. По крайней мере, на 6 миллионов рабочих больше, чем десять лет назад. Даже богатые доходами компании, такие как Google и Meta, передают на аутсорсинг такие функции, как уборка, питание и некоторые технические рабочие места, исключая многих людей, которые работают в своих офисах, из преимуществ полной занятости.

© Adria Malcolm for TIME
Отношения между Даниэлем Барелой-младшим, левым и старшим были напряженными из-за борьбы Даниэля-младшего почувствовать себя средним классом
В то же время неуклонный рост автоматизации и технологий означает, что все больше работодателей хотят иметь работников с высшим образованием. Согласно исследованию Гарварда, около двух третей рабочих мест руководителей производства в 2015 году требовали наличия высшего образования, в то время как только 16% уже работающих начальников производства имели его.
Отец бортпроводника Даниэля Барелы Дэниел Барела-старший не может понять, почему его дети борются. Когда он впервые переехал в Альбукерке в 1984 году, он зарабатывал 5,40 доллара в час в качестве сторожа. У него нет высшего образования, но он продвинулся в своей компании и купил дом, в котором вырос Дэниел. Сейчас он и его жена владеют девятью объектами недвижимости в Нью-Мексико.
«Мое поколение — мы не заканчивали неделю в 40 часов», — говорит он. «Все началось в 40 часов, если вы хотели добиться успеха, и мы сделали все, что нужно. Это поколение — в 40 часов они истощены. Они не зря называют это поколение «Я».
У старшего Барелы есть пенсия, которую люди на его месте сегодня не получали бы. И он признает, что жилье стоит дороже, чем было, когда он покупал недвижимость. Но он также был удивлен, как трудно найти кого-то, кто помог бы ему отремонтировать одну из его арендуемых квартир за 12-15 долларов в час. «Это не только мои дети. Я вижу это у других детей — они просто не хотят работать», — говорит он.
Это безмерно расстраивает его сына. Он потратил долгие часы, чтобы продвинуться в авиационной отрасли, и до сих пор не может даже претендовать на владение домом. Всякий раз, когда он получает повышение, говорит он, взносы на медицинское страхование и другие расходы растут на ту же сумму. Это не просто его воображение. По данным Института Людвига, учитель и водитель скорой помощи в Альбукерке зарабатывают 77 000 долларов в год, что выше, чем средний доход в США в 67 000 долларов, но им все равно придется влезать в долги на 6 000 долларов, чтобы удовлетворять свои минимальные адекватные потребности каждый год.
Во время пандемии Барела почувствовал, какой могла быть жизнь его отца. По его словам, поскольку он был уволен и получал пособие по безработице и стимулирующие деньги, он смог погасить весь свой долг. Теперь, когда он снова работает, он снова использует кредитные карты и живет от зарплаты до зарплаты.
Доходит до того, что Барела чувствует, что он должен просто исполнить пророчество своего отца и перестать так сильно стараться. Тяжелый труд никуда его не привел. Зачем тратить больше времени на общение с разгневанными пассажирами из-за оплаты, которая будет съедена счетами? «Я думаю, во всяком случае, COVID научил нас: стоит ли работать до мозга костей ради качества жизни?» он говорит. «Для себя я начну просто поддерживать то, что мне нужно, но я не собираюсь прогибаться назад, чтобы выполнить какую-то корпоративную мантру».
«Абсолютно нелепо, что можно иметь две самые важные работы и при этом едва позволить себе жить. Я ненавижу эту страну».
Он, как и Джефф Своуп, и многие другие люди, опрошенные для этой статьи, направляет большую часть своего разочарования на очень богатых, которые накапливают богатство в виде инвестиций, которые облагаются налогом по гораздо более низкой ставке, чем заработная плата. Широкое недовольство и сокращение рядов среднего класса давно связывают с политической нестабильностью. Во времена большого экономического неравенства богатые угнетали бедных или бедные стремились конфисковать богатство богатых, что приводило к насилию и революции. Но присутствие среднего класса помогло Америке избежать этого конфликта, говорит профессор права Университета Вандербильта Ганеш Ситараман. Вот почему он утверждает, что «угроза номер один для американского конституционного правительства сегодня — это крах среднего класса».
Не случайно уменьшение веры американцев в свои институты стало отражением упадка состояния среднего класса. И президент Байден, который долгое время считал себя защитником тех, кто находится посередине, тем не менее теряет их поддержку; только треть людей одобрили его управление экономикой в мартовском опросе NBC, что на 5 процентных пунктов меньше, чем в январе.
Некоторые экономисты считают, что годы после Второй мировой войны были аномалией — периодом беспрецедентного роста производительности и процветания, который никогда не повторится. Миллионы людей поступили в колледжи по закону о военнослужащих, и заработная плата резко возросла, что позволило семьям покупать дома, машины и телевизоры.
Это означает, что сравнение работников среднего класса с их родителями может быть не самым полезным способом измерения их экономического положения. Если их детство пришлось на период исключительного экономического роста, неудивительно, что такие люди, как Своуп и Барела, сегодня чувствуют себя обделенными. Более того, предыдущие поколения не позволяли многим американцам, в том числе цветным и женщинам, работать и владеть домами. «Одна из причин, по которой американцы из среднего класса могли добиться таких успехов раньше, заключалась в том, что они исключали людей из рынка труда, и у них были сильные профсоюзы, которые давали им более высокую заработную плату, чем мог бы дать им рынок», — говорит Ривз.
Приспособиться к новому миру будет непросто. Ривз предостерегает семьи сравнивать себя не с поколением своих родителей, а с тем, где они были бы без политических мер во время Великой рецессии и пандемического спада. Где была бы американская экономика, если бы правительство не спасло банки и автомобильные компании? Что, если бы он не приостановил выплаты по студенческим кредитам во время пандемии и не разослал чеки на стимулирование и налоговые льготы на детей? Если бы семьи могли сравнивать себя с гипотетическими, они, возможно, не так злились бы — и, возможно, их гнев не было бы так легко использовать в качестве оружия против тех, кто, по их мнению, создал их экономические проблемы, будь то люди разных рас или крупный бизнес.
Некоторое время назад, после того, как Джефф Своп узнал о росте цен в своем жилом комплексе, он опубликовал что-то в группе Facebook под названием "Никто не хочет работать", которая высмеивала все предприятия, жалующиеся на то, что они не могут найти рабочих, в то время как они предлагают минимальную заработную плату за ужасные рабочие места.
«Медсестра и учитель с семейным доходом в 125 тысяч долларов почти не смогут обойтись без каких-либо сбережений. Это так плохо», — написал он. Некоторые комментаторы обвинили его в плохом управлении деньгами. Они не могли сочувствовать тому, кто получает шестизначный доход и все еще испытывает трудности.
Но многие другие из сотен комментаторов чувствовали что-то другое — что они точно знали, что чувствует Своуп. «Мы с моим парнем работаем в профсоюзе на сталелитейном заводе и находимся примерно в одной лодке», — написал один из них. Другая, тоже медсестра, писала, что они с мужем, инженером, тоже живут от зарплаты до зарплаты. В комментариях их ярость была безудержной. «Абсолютно нелепо, что можно иметь две самые важные работы и при этом едва позволить себе жить», — сказал другой комментатор. «Я ненавижу эту страну».
С репортажем Лесли Дикштейн / Нью-Йорк
За последние два десятилетия медицинские расходы, как правило, росли быстрее, чем инфляция, что было вызвано увеличением стоимости медицинского обслуживания и увеличением спроса на услуги из-за старения населения. Национальные расходы на здравоохранение на душу населения в 1980 году с поправкой на инфляцию составили 2968 долларов; к 2020 году это было в четыре раза больше. Пандемия усугубила проблемы, так как многие люди потеряли работу и страховку. Согласно опросу, проведенному Фондом Содружества, более половины взрослых, заразившихся COVID-19 или потерявших доход во время пандемии, также столкнулись с проблемами, связанными с медицинскими счетами.
Высшее образование, третье H, также неуклонно дорожало, поскольку стоимость обучения в колледже росла, а федеральное финансирование государственных университетов резко падало. По мере роста цен все больше студентов брали кредиты. Средний долг по студенческой ссуде в 2020 году составлял 36 635 долларов, что примерно вдвое больше, чем в 1990 году, с поправкой на инфляцию. Семьи десятилетиями борются за то, чтобы не отставать от выплат. Грин думала, что выделяет себя, когда поступила в частный колледж, чтобы получить степень медсестры. Теперь она должна кредита на 99 000 долларов, а две ее сестры, которые не учились в колледже, свободны от долгов.
Для многих выпускников колледжей пандемия принесла некоторое облегчение, когда Закон CARES приостановил выплаты по федеральным студенческим кредитам. Внезапно у людей появились деньги, чтобы оплачивать другие счета, и они увидели, какой будет жизнь без калечащих студенческих долгов. Грин смотрела приложение на своем телефоне, когда ее кредит остановился на 99 000 долларов — и остался там. Она боится, когда снова начнутся выплаты.
В целом, три «Н» — арендная плата, здравоохранение и ссуды на высшее образование — занимают растущую долю получаемой Своупом и Грином заработной платы. Добавьте предметы первой необходимости, такие как еда и коммунальные услуги, и у них будут месяцы, когда они будут выписывать чеки за аренду, не имея достаточно денег на своем текущем счете. (Swope получает зарплату ежемесячно.) Они не едят вне дома. Они переключились на общие продуктовые бренды. Хотя они оба работают полный рабочий день, Своуп рассматривает возможность подработки.
Некоторые экономисты утверждают, что бедственное положение среднего класса маскируется плохим бухгалтерским учетом. Юджин Людвиг, бывший контролер денежного обращения в администрации Клинтона, говорит, что индекс потребительских цен искажает реальную экономическую картину для американцев с низким и средним уровнем доходов, поскольку он учитывает стоимость необязательных предметов, таких как яхты, вторые дома и гостиничные номера. По его подсчетам, стоимость минимальных потребностей домохозяйства выросла на 64% с 2001 по 2020 год, что на 1,4% быстрее инфляции. В марте Институт совместного экономического процветания Людвига опубликовал отчет, в котором говорилось, что цены на жилье фактически выросли на 149% (ИПЦ оценил их на 54%), а расходы на медицинское обслуживание выросли на 157% (по сравнению с 90%).
«Мы обнаружили, что, хотя в 2001 году у людей, возможно, были лишь небольшие дискреционные расходы, к 2019 году для сравнения их не было во многих семьях, особенно в семьях с большим количеством детей», — говорит исполнительный директор Института Людвига Стефани Аллен. (По ее словам, с тех пор пандемия сделала отслеживание этих данных слишком ненадежным для оценки дискреционных расходов.)
Стресс и гнев, которые испытывают люди в возрасте от 30 до 40 лет, распространяются на их отношения с поколением их родителей. Сегодня семья в США, имеющая средний доход на домохозяйство, должна платить в шесть раз больше этого дохода, чтобы купить дом по средней цене. В 1980 году им пришлось бы платить вдвойне. Но многие бумеры, кажется, не очень сочувствуют затруднительному положению своих детей. Отец Джеффа Своупа смог содержать семью из трех человек на зарплату социального работника и купил дом в Сэнди-Спрингс, штат Джорджия, примерно за 50 000 долларов. Его мать продала его в прошлом году за 255 000 долларов, а тот покупатель продал его в марте на 30% дороже.
Своуп, с другой стороны, окончил колледж со степенью в области маркетинга в 2003 году и устроился продавать рекламу в «Желтых страницах». Когда этот бизнес исчез с распространением поисковых систем в Интернете, он работал официантом и получил второе высшее образование, чтобы преподавать. Он получил высшее образование в 2008 году в разгар Великой рецессии и зарабатывал себе на жизнь, работая ведущим викторин и занимая любые места преподавания, которые он мог найти.
До 2013 года он не устраивался на работу учителем начального уровня в государственной школе. Даже сейчас его дохода в 55 000 долларов недостаточно, чтобы прокормить семью. Он и Грин подали заявку на предварительное одобрение ипотеки, но не получили ответа. Он чувствует себя застрявшим. «Это похоже на то, что ты не взрослый, если у тебя нет дома», — говорит он. «Старшее поколение смотрит на вас свысока, потому что просто не понимает».
Одна из вещей, которую некоторым людям труднее понять, — это волновые эффекты структурных изменений, которые только начинались, когда они были моложе. Например, из-за упадка профсоюзов, длившегося несколько десятилетий, рабочим стало труднее вести переговоры о повышении заработной платы и пособий. Своуп не состоит в профсоюзе учителей, потому что в Джорджии запрещены коллективные переговоры для государственных педагогов, что является одной из причин, по которой средний учитель государственной школы зарабатывал в 2020–2021 учебном году на 5% меньше, чем в 1999–2000 годах, с поправкой на инфляцию. В Массачусетсе, штате с сильными профсоюзами учителей, средняя заработная плата учителя государственной школы за тот же период выросла на 19%.
По всей стране становится все труднее найти работу с медицинским обслуживанием и другими льготами. По крайней мере, на 6 миллионов рабочих больше, чем десять лет назад. Даже богатые доходами компании, такие как Google и Meta, передают на аутсорсинг такие функции, как уборка, питание и некоторые технические рабочие места, исключая многих людей, которые работают в своих офисах, из преимуществ полной занятости.
© Adria Malcolm for TIME
Отношения между Даниэлем Барелой-младшим, левым и старшим были напряженными из-за борьбы Даниэля-младшего почувствовать себя средним классом
В то же время неуклонный рост автоматизации и технологий означает, что все больше работодателей хотят иметь работников с высшим образованием. Согласно исследованию Гарварда, около двух третей рабочих мест руководителей производства в 2015 году требовали наличия высшего образования, в то время как только 16% уже работающих начальников производства имели его.
Отец бортпроводника Даниэля Барелы Дэниел Барела-старший не может понять, почему его дети борются. Когда он впервые переехал в Альбукерке в 1984 году, он зарабатывал 5,40 доллара в час в качестве сторожа. У него нет высшего образования, но он продвинулся в своей компании и купил дом, в котором вырос Дэниел. Сейчас он и его жена владеют девятью объектами недвижимости в Нью-Мексико.
«Мое поколение — мы не заканчивали неделю в 40 часов», — говорит он. «Все началось в 40 часов, если вы хотели добиться успеха, и мы сделали все, что нужно. Это поколение — в 40 часов они истощены. Они не зря называют это поколение «Я».
У старшего Барелы есть пенсия, которую люди на его месте сегодня не получали бы. И он признает, что жилье стоит дороже, чем было, когда он покупал недвижимость. Но он также был удивлен, как трудно найти кого-то, кто помог бы ему отремонтировать одну из его арендуемых квартир за 12-15 долларов в час. «Это не только мои дети. Я вижу это у других детей — они просто не хотят работать», — говорит он.
Это безмерно расстраивает его сына. Он потратил долгие часы, чтобы продвинуться в авиационной отрасли, и до сих пор не может даже претендовать на владение домом. Всякий раз, когда он получает повышение, говорит он, взносы на медицинское страхование и другие расходы растут на ту же сумму. Это не просто его воображение. По данным Института Людвига, учитель и водитель скорой помощи в Альбукерке зарабатывают 77 000 долларов в год, что выше, чем средний доход в США в 67 000 долларов, но им все равно придется влезать в долги на 6 000 долларов, чтобы удовлетворять свои минимальные адекватные потребности каждый год.
Во время пандемии Барела почувствовал, какой могла быть жизнь его отца. По его словам, поскольку он был уволен и получал пособие по безработице и стимулирующие деньги, он смог погасить весь свой долг. Теперь, когда он снова работает, он снова использует кредитные карты и живет от зарплаты до зарплаты.
Доходит до того, что Барела чувствует, что он должен просто исполнить пророчество своего отца и перестать так сильно стараться. Тяжелый труд никуда его не привел. Зачем тратить больше времени на общение с разгневанными пассажирами из-за оплаты, которая будет съедена счетами? «Я думаю, во всяком случае, COVID научил нас: стоит ли работать до мозга костей ради качества жизни?» он говорит. «Для себя я начну просто поддерживать то, что мне нужно, но я не собираюсь прогибаться назад, чтобы выполнить какую-то корпоративную мантру».
«Абсолютно нелепо, что можно иметь две самые важные работы и при этом едва позволить себе жить. Я ненавижу эту страну».
Он, как и Джефф Своуп, и многие другие люди, опрошенные для этой статьи, направляет большую часть своего разочарования на очень богатых, которые накапливают богатство в виде инвестиций, которые облагаются налогом по гораздо более низкой ставке, чем заработная плата. Широкое недовольство и сокращение рядов среднего класса давно связывают с политической нестабильностью. Во времена большого экономического неравенства богатые угнетали бедных или бедные стремились конфисковать богатство богатых, что приводило к насилию и революции. Но присутствие среднего класса помогло Америке избежать этого конфликта, говорит профессор права Университета Вандербильта Ганеш Ситараман. Вот почему он утверждает, что «угроза номер один для американского конституционного правительства сегодня — это крах среднего класса».
Не случайно уменьшение веры американцев в свои институты стало отражением упадка состояния среднего класса. И президент Байден, который долгое время считал себя защитником тех, кто находится посередине, тем не менее теряет их поддержку; только треть людей одобрили его управление экономикой в мартовском опросе NBC, что на 5 процентных пунктов меньше, чем в январе.
Некоторые экономисты считают, что годы после Второй мировой войны были аномалией — периодом беспрецедентного роста производительности и процветания, который никогда не повторится. Миллионы людей поступили в колледжи по закону о военнослужащих, и заработная плата резко возросла, что позволило семьям покупать дома, машины и телевизоры.
Это означает, что сравнение работников среднего класса с их родителями может быть не самым полезным способом измерения их экономического положения. Если их детство пришлось на период исключительного экономического роста, неудивительно, что такие люди, как Своуп и Барела, сегодня чувствуют себя обделенными. Более того, предыдущие поколения не позволяли многим американцам, в том числе цветным и женщинам, работать и владеть домами. «Одна из причин, по которой американцы из среднего класса могли добиться таких успехов раньше, заключалась в том, что они исключали людей из рынка труда, и у них были сильные профсоюзы, которые давали им более высокую заработную плату, чем мог бы дать им рынок», — говорит Ривз.
Приспособиться к новому миру будет непросто. Ривз предостерегает семьи сравнивать себя не с поколением своих родителей, а с тем, где они были бы без политических мер во время Великой рецессии и пандемического спада. Где была бы американская экономика, если бы правительство не спасло банки и автомобильные компании? Что, если бы он не приостановил выплаты по студенческим кредитам во время пандемии и не разослал чеки на стимулирование и налоговые льготы на детей? Если бы семьи могли сравнивать себя с гипотетическими, они, возможно, не так злились бы — и, возможно, их гнев не было бы так легко использовать в качестве оружия против тех, кто, по их мнению, создал их экономические проблемы, будь то люди разных рас или крупный бизнес.
Некоторое время назад, после того, как Джефф Своп узнал о росте цен в своем жилом комплексе, он опубликовал что-то в группе Facebook под названием "Никто не хочет работать", которая высмеивала все предприятия, жалующиеся на то, что они не могут найти рабочих, в то время как они предлагают минимальную заработную плату за ужасные рабочие места.
«Медсестра и учитель с семейным доходом в 125 тысяч долларов почти не смогут обойтись без каких-либо сбережений. Это так плохо», — написал он. Некоторые комментаторы обвинили его в плохом управлении деньгами. Они не могли сочувствовать тому, кто получает шестизначный доход и все еще испытывает трудности.
Но многие другие из сотен комментаторов чувствовали что-то другое — что они точно знали, что чувствует Своуп. «Мы с моим парнем работаем в профсоюзе на сталелитейном заводе и находимся примерно в одной лодке», — написал один из них. Другая, тоже медсестра, писала, что они с мужем, инженером, тоже живут от зарплаты до зарплаты. В комментариях их ярость была безудержной. «Абсолютно нелепо, что можно иметь две самые важные работы и при этом едва позволить себе жить», — сказал другой комментатор. «Я ненавижу эту страну».
С репортажем Лесли Дикштейн / Нью-Йорк
Аналитик составяющий свое заключение по неполным данным подобен игроку ставящему на число рулетки.
Взгляды отдельных авторов не обязательно отражают мою точку зрения
Гиперссылка на оригинальный материал находится в заголовке каждой статьи
Взгляды отдельных авторов не обязательно отражают мою точку зрения
Гиперссылка на оригинальный материал находится в заголовке каждой статьи
66 лет
Карма: +14.72
Регистрация: 16.11.2008
Сообщений: 4,046
Читатели: 4
Регистрация: 16.11.2008
Сообщений: 4,046
Читатели: 4
Чжао Яньцзин: Валюта - это второе поле боя российско-украинской войны?
Чжао Яньцзин, профессор
2022-04-29
Битва между Россией и Украиной была частью великих перемен, которых не было уже сто лет. Поскольку это “беспрецедентно за сто лет”, это означает, что логика, стоящая за этим, вероятно, является чем-то таким, с чем мы никогда раньше не сталкивались. После войны между Россией и Украиной большая часть внимания мира была сосредоточена на быстро меняющемся поле боя Украины, но она игнорировала, что глобальная валютная война может быть частью айсберга, скрытого под водой.
1. Поле боя за пределами поля боя
Стратегический фокус Соединенных Штатов внезапно сместился с Китая на Россию не потому, что китайская угроза уменьшилась, а потому, что большая опасность вынудила Соединенные Штаты скорректировать приоритет стратегического выбора. Этой неминуемой опасностью является столица Соединенных Штатов. В частности, это доллар США.
Недавний разворот доходности американских облигаций показывает, что самая большая опасность для доллара США заключается в том, что валюта может перейти от недостаточного предложения к избыточному. В частности, инфляция привела к падению реальной доходности долларовых активов США, что усилило давление на рынок с целью отказа от долларовых активов США.
Как только доллар США нарушит баланс спроса и предложения, доллар США рухнет. В условиях новой коронной пандемии вместо того, чтобы сократить предложение доллара, он был вынужден еще больше ослабить его, поэтому он может только повернуться на сторону спроса, чтобы предотвратить крах валюты. Первое, что нужно сделать, чтобы предотвратить падение спроса, - это подавить любую альтернативную валюту, которая может бросить вызов доллару США.
Независимой валютой, которая, скорее всего, заменит доллар США, является евро. Согласно статистике Глобальной межбанковской ассоциации финансовых телекоммуникаций (SWIFT), на доллар США в январе 2022 года пришлось 39,92% доли международных расчетов, а на евро - 36,56%. Евро является наиболее вероятной международной валютой для замены доллара США.
После немедленного подавления зарождающегося евро войной 1999 года в Косово трудно не создать впечатления, что Соединенные Штаты поощряют российско-украинскую напряженность не против России, а против евро. На первый взгляд это вооруженный конфликт, но за ним стоит валютная война.
Да, российско-украинская война была инициирована Россией, но именно Соединенные Штаты поддерживали напряженность между Россией и Украиной и способствовали ее постепенной эскалации. Вспышка российско-украинского конфликта - это не что иное, как совокупный результат российско-украинской напряженности.
На международном платежном рынке в первом квартале 2020 года доля евро полностью упала - до 33,58%, 32,61%, 30,84%.Вторжение России на Украину означает, что возможности для евро бросить вызов доллару больше не существует.
В валютной войне между долларом США и евро Украина и даже Россия изначально были пешками. В течение последнего месяца или около того курс рубля испытывал огромные колебания. После того как российская сторона объявила о начале специальной военной операции 24 февраля, рубль начал проявлять признаки стремительного обесценивания. Курс по отношению к доллару США в тот же день опустился ниже 80 к 1. С интенсивным выпуском западных экономических санкций рубль резко упал полностью, и 9 марта он упал ниже 120 к 1, что является рекордно низким показателем.
Столкнувшись с финансовой войной, в которой Соединенные Штаты пытались вытеснить российские ресурсы из Европы, Россия неожиданно вышла победителем, чего не ожидали все участники рынка. Начиная с 1 апреля, с подписания президентом Путиным, указа, что все недружественные России страны должны будут покупать природный газ за рубли. Россия внезапно превратилась из шахматной фигуры в шахматиста, прямо захватив берег на валютном рынке, открыв второе поле битвы между Соединенными Штатами и Россией.
Шокирующий шаг России не только быстро остановил обвал рубля, но и объявил о монетарной регенерации, подготовленной физической валютой после Бреттон-Вудской системы. По данным Московской биржи, по состоянию на закрытие торгов 7-го числа курс рубля к доллару США вырос до 75,75 к 1, а курс к евро - до 81,45 к 1; внутридневной курс рубля к доллару США вырос до 74,26 к 1, а обменный курс по отношению к евро вырос до 80,69 к 1.

В этом году Беларусь будет платить за российскую нефть и газ в российских рублях. Источник изображения: Vision China
После того как в прошлую пятницу Центральный банк России снизил базовую процентную ставку на 300 базисных пунктов до 17%, курс рубля по отношению к доллару США за короткий промежуток времени подскочил до недавнего максимума в 71 рубль за доллар США. по отношению к доллару США на прошлой неделе он вырос более чем на 9%.
Первоначальная идея Соединенных Штатов состояла в том, чтобы использовать Украину в качестве агента без необходимости лично спускаться вниз и убить двух зайцев одним выстрелом: блокируя интеграцию России и Европы, они “афганизировали” бы Украину и обескровили бы Россию. Но контратака России на валютном рынке вынудила США выйти на боксерский ринг.
На первый взгляд, России не удалось воспроизвести крымское быстрое решение на поле боя, но тупиковая ситуация в конфликте создала условия для России, чтобы захватить пляж в Нормандии - валюту и до тех пор, пока продолжающаяся война между Россией и Украиной может поддерживать глобальную нехватку продовольствия и энергоносителей, сырьевых товаров Он должен иметь глобальную ликвидность, и даже если рубль, привязанный к оптовым товарам, не привязан к евро, он сам может стать твердой валютой. Если Соединенные Штаты не смогут надолго снизить цены на энергоносители, как это было в конце холодной войны, Россия не падет, как Советский Союз. Для США, которые изначально хотели использовать российско-украинский конфликт для укрепления долларового барьера, он стал очень пассивным. США отрезали российскую энергетическую поддержку евро, но не ожидали, что рубль бросит вызов базе кредитной валюты в виде физической валюты.
Хотя рубль невелик, он может стать первым темным облаком, появившимся на темном горизонте Бреттон-Вудса III (Золтан Позар, 2022).Отделение оптовых товаров от кредитного валютного ценообразования неизбежно приведет к снижению спроса на доллары США и евро. Если другие богатые ресурсами страны вместе последуют рублевой модели, спрос на доллар США может резко упасть, и в противном случае невозможный Бреттон-Вудс III может внезапно наступить, прорвав огромный пузырь доллара США. Это особенно опасно для уже сильно перевыпущенного доллара.
В условиях сегодняшней глобализации у физических валют вообще нет никаких шансов. Причина, по которой кредитная валюта может подавить традиционную физическую валюту, заключается в том, что история кредитной валюты решает проблему нехватки валюты раз и навсегда. После краха Бреттон-Вудской системы великое экономическое процветание, основанное на кредитных деньгах, заставило людей поверить, что физическая валюта была отправлена в Музей истории денег раз и навсегда.
Однако, когда валюта вступает в экономический цикл переизбытка предложения, огромный масштаб становится слабостью кредитной валюты. Особенно в условиях новой пандемии короны доллар США отказался от выдачи кредитных требований в валюте, принял MMT без какой-либо корреспонденции по активам и напрямую выдал деньги резидентам. Модель напрямую вызвала большую инфляцию, которой не было бы в исходном кредите на выпуск валюты. До сих пор годовые темпы роста ИПЦ, которые Федеральная резервная система считает временным явлением, достигали или превышали 5% в течение одиннадцати месяцев подряд.
После начала российско-украинской войны инфляция в США не ослабевает. 12 апреля Бюро статистики труда США опубликовало данные, показывающие, что индекс потребительских цен США вырос на 8,5% в годовом исчислении в марте, опередив предыдущее значение в 7,9%, которое также было выше ожиданий рынка в 8,4%, что является самым быстрым темпом роста с декабря 1981 года. Если российско-украинский конфликт продолжит подталкивать вверх цены на энергоносители и продовольствие, доллару США и евро придется повысить процентные ставки.
На самом деле рынок уже отреагировал на эту перспективу доллара США. 11 апреля доходность 20-летних казначейских облигаций США сильно выросла примерно на 9 базисных пунктов до 3,01%, установив самый высокий рекорд с тех пор, как Министерство финансов США возобновило выпуск 20-летних казначейских облигаций в мае 2020 года. Если процентные ставки не будут повышены, казначейские облигации США будут распроданы из-за отрицательной доходности, а если процентные ставки будут повышены, то европейские и американские рынки капитала сократятся.
В это время первоначально безнадежная физическая деноминированная валюта стала единственным ковчегом, который мог сохранить богатство во время великого потопа. Поэтому, даже если прогресс России на первом поле боя будет неблагоприятным, пока российско-украинская война может втянуть мировую экономику в серьезный спад, физически деноминированная российская экономика может выжить до конца на втором поле боя. Даже подобно Советскому Союзу в первой пятилетке, не задумываясь скопировать активы развитых стран и завершить перепрофилирование промышленности.
Попытка Соединенных Штатов обрушить российскую экономику с помощью войны может не только провалиться, но и позволить России успешно избежать грядущей Великой депрессии, как это было в бывшем Советском Союзе и Китайской Республике с серебряным стандартом. Бохайские монеты, подготовленные к выпуску базовой базой Шаньдун с материалами во время Войны Сопротивления, показали, что в условиях кредитного коллапса реальной валютой были физические объекты. Как сказал Позар: "Вы можете печатать деньги, но вы не можете печатать нефть и пшеницу”.
2. Роль Китая в шахматной игре
Хотя ВВП занимает второе место в мире, угроза Китая для экономики США гораздо меньше, чем кажется на первый взгляд. Угроза евро Соединенным Штатам глубока, а влияние Китая на Соединенные Штаты неглубоко.
Если под долларом США понимать глобализацию как "Олимпийские игры”, то евро - это “Чемпионат мира”, независимый от доллара США. Битва между Европой и Соединенными Штатами - это рыночная битва между двумя основными игроками. Так называемая “китайская угроза” происходит просто потому, что Китай выиграл слишком много медалей и слишком много говорит на “Олимпийских играх”, а сам он не представляет угрозы для “Олимпийских игр”, в которых доминирует доллар Соединенных Штатов. Чем недоволен Китай, так это американскими конкурсантами (группами производственных интересов), которые хотят обеспечить себе медали, исключив Китай из “Олимпийских игр”.
Соединенные Штаты борются с тем, что без таких игроков, как Китай, “Олимпийские игры” (доллар США) будут непривлекательными и будут заменены “Чемпионатом мира” (евро). Поэтому финансовые группы, проводящие “Олимпийские игры”, и производственные группы, участвующие в конкурсе, непоследовательно относятся к интересам Китая. Результатом компромисса между двумя сторонами является подготовка китайских конкурентов (таких как Индия и Вьетнам) и, при необходимости, исключение китайских конкурентоспособных игроков из индивидуальных соревнований. Снизить зависимость от единого продукта китайского производства и сохранить доминирование США над различными правилами (мировым порядком) “Олимпийских игр”.
Причина, по которой Соединенные Штаты внезапно обратили свой взор на Россию, заключается в том, что когда Европа и Россия используют всю мощь Соединенных Штатов для борьбы с Китаем, они вот-вот завершат экономическую интеграцию, основанную на энергетике и валюте. Как только интеграция России и Европы будет успешной, привлекательность “Чемпионата мира” (евро) может превысить привлекательность “Олимпийских игр” (долларов США), а реклама (капитал), первоначально выделенная на “Олимпийские игры” (долларов США), может переместиться на “Чемпионат мира” (евро).
Перед лицом грядущего финансового кризиса любая потеря капитала может оказаться фатальной. Это вынудило Соединенные Штаты временно свернуть клиринговый портал против Китая и ликвидировать неминуемую угрозу российско-европейской интеграции, взорвав российско-украинский конфликт. В этом вопросе у Китая и США, которые оба являются “большими золотыми медалистами” на Олимпийских играх, есть общие интересы.
Реальный мир определенно сложнее, чем Олимпиада против чемпионата мира. Но это виртуальное соревнование может лаконично изобразить роль Китая в этой игре великих держав. В этой игре великих держав китайско-американский конфликт и европейско-американский конфликт существенно отличаются друг от друга.
Независимо от того, насколько велика экономика Китая, она является частью долларовой зоны. В то время как еврозона, по-видимому, является союзником Соединенных Штатов, Соединенные Штаты совершенно ясно понимают, что евро является самой большой угрозой. Как только будет обнаружено, что евро может воспользоваться кризисом доллара, чтобы заменить его, Соединенные Штаты немедленно развернут свое оружие и сделают стратегическим приоритетом подавление евро.
По той же логике можно резонно предположить, что если российско-украинский конфликт ввергнет доллар в кризис, то можно быстро достичь урегулирования между Китаем и США. Хотя сейчас эта возможность кажется очень маленькой, она не совсем невозможна. До "Сианьского инцидента” кто бы мог подумать, что две стороны Коммунистической партии Китая смогут сотрудничать в "кровавом море ненависти"? Однако Япония начала агрессивную войну против Китая, так что это, казалось бы, крайне маловероятное событие произошло. Япония, более серьезная угроза, побудила Коммунистическую партию Китая пойти на второе сотрудничество, которого ни одна из сторон не ожидала.
Несмотря на огромные размеры экономики Китая, он далек от того, чтобы быть крупным игроком в мировой серии. Китай может выбирать, в ком участвовать, но у него еще нет возможности проводить свои собственные мероприятия. Независимо от того, сколько золотых медалей вы выиграете, вы находитесь на чужой домашней площадке. В этом отношении у нас должно быть четкое понимание. Не думайте, что ВВП превышает Европейский Союз, просто подумайте, что вы можете стать полюсом мира, потому что только обладая глобальным и незаменимым капиталом - рынками капитала (США и Европа), энергии (США и Россия), продовольствия (США и Россия), технологии (США, Япония и Европа) и т.д. - Вы можете стать глобальной валютой, и только если у вас есть глобальная валюта, кто-то будет участвовать в проводимых вами мероприятиях.
Чжао Яньцзин, профессор
2022-04-29
Битва между Россией и Украиной была частью великих перемен, которых не было уже сто лет. Поскольку это “беспрецедентно за сто лет”, это означает, что логика, стоящая за этим, вероятно, является чем-то таким, с чем мы никогда раньше не сталкивались. После войны между Россией и Украиной большая часть внимания мира была сосредоточена на быстро меняющемся поле боя Украины, но она игнорировала, что глобальная валютная война может быть частью айсберга, скрытого под водой.
1. Поле боя за пределами поля боя
Стратегический фокус Соединенных Штатов внезапно сместился с Китая на Россию не потому, что китайская угроза уменьшилась, а потому, что большая опасность вынудила Соединенные Штаты скорректировать приоритет стратегического выбора. Этой неминуемой опасностью является столица Соединенных Штатов. В частности, это доллар США.
Недавний разворот доходности американских облигаций показывает, что самая большая опасность для доллара США заключается в том, что валюта может перейти от недостаточного предложения к избыточному. В частности, инфляция привела к падению реальной доходности долларовых активов США, что усилило давление на рынок с целью отказа от долларовых активов США.
Как только доллар США нарушит баланс спроса и предложения, доллар США рухнет. В условиях новой коронной пандемии вместо того, чтобы сократить предложение доллара, он был вынужден еще больше ослабить его, поэтому он может только повернуться на сторону спроса, чтобы предотвратить крах валюты. Первое, что нужно сделать, чтобы предотвратить падение спроса, - это подавить любую альтернативную валюту, которая может бросить вызов доллару США.
Независимой валютой, которая, скорее всего, заменит доллар США, является евро. Согласно статистике Глобальной межбанковской ассоциации финансовых телекоммуникаций (SWIFT), на доллар США в январе 2022 года пришлось 39,92% доли международных расчетов, а на евро - 36,56%. Евро является наиболее вероятной международной валютой для замены доллара США.
После немедленного подавления зарождающегося евро войной 1999 года в Косово трудно не создать впечатления, что Соединенные Штаты поощряют российско-украинскую напряженность не против России, а против евро. На первый взгляд это вооруженный конфликт, но за ним стоит валютная война.
Да, российско-украинская война была инициирована Россией, но именно Соединенные Штаты поддерживали напряженность между Россией и Украиной и способствовали ее постепенной эскалации. Вспышка российско-украинского конфликта - это не что иное, как совокупный результат российско-украинской напряженности.
На международном платежном рынке в первом квартале 2020 года доля евро полностью упала - до 33,58%, 32,61%, 30,84%.Вторжение России на Украину означает, что возможности для евро бросить вызов доллару больше не существует.
В валютной войне между долларом США и евро Украина и даже Россия изначально были пешками. В течение последнего месяца или около того курс рубля испытывал огромные колебания. После того как российская сторона объявила о начале специальной военной операции 24 февраля, рубль начал проявлять признаки стремительного обесценивания. Курс по отношению к доллару США в тот же день опустился ниже 80 к 1. С интенсивным выпуском западных экономических санкций рубль резко упал полностью, и 9 марта он упал ниже 120 к 1, что является рекордно низким показателем.
Столкнувшись с финансовой войной, в которой Соединенные Штаты пытались вытеснить российские ресурсы из Европы, Россия неожиданно вышла победителем, чего не ожидали все участники рынка. Начиная с 1 апреля, с подписания президентом Путиным, указа, что все недружественные России страны должны будут покупать природный газ за рубли. Россия внезапно превратилась из шахматной фигуры в шахматиста, прямо захватив берег на валютном рынке, открыв второе поле битвы между Соединенными Штатами и Россией.
Шокирующий шаг России не только быстро остановил обвал рубля, но и объявил о монетарной регенерации, подготовленной физической валютой после Бреттон-Вудской системы. По данным Московской биржи, по состоянию на закрытие торгов 7-го числа курс рубля к доллару США вырос до 75,75 к 1, а курс к евро - до 81,45 к 1; внутридневной курс рубля к доллару США вырос до 74,26 к 1, а обменный курс по отношению к евро вырос до 80,69 к 1.
В этом году Беларусь будет платить за российскую нефть и газ в российских рублях. Источник изображения: Vision China
После того как в прошлую пятницу Центральный банк России снизил базовую процентную ставку на 300 базисных пунктов до 17%, курс рубля по отношению к доллару США за короткий промежуток времени подскочил до недавнего максимума в 71 рубль за доллар США. по отношению к доллару США на прошлой неделе он вырос более чем на 9%.
Первоначальная идея Соединенных Штатов состояла в том, чтобы использовать Украину в качестве агента без необходимости лично спускаться вниз и убить двух зайцев одним выстрелом: блокируя интеграцию России и Европы, они “афганизировали” бы Украину и обескровили бы Россию. Но контратака России на валютном рынке вынудила США выйти на боксерский ринг.
На первый взгляд, России не удалось воспроизвести крымское быстрое решение на поле боя, но тупиковая ситуация в конфликте создала условия для России, чтобы захватить пляж в Нормандии - валюту и до тех пор, пока продолжающаяся война между Россией и Украиной может поддерживать глобальную нехватку продовольствия и энергоносителей, сырьевых товаров Он должен иметь глобальную ликвидность, и даже если рубль, привязанный к оптовым товарам, не привязан к евро, он сам может стать твердой валютой. Если Соединенные Штаты не смогут надолго снизить цены на энергоносители, как это было в конце холодной войны, Россия не падет, как Советский Союз. Для США, которые изначально хотели использовать российско-украинский конфликт для укрепления долларового барьера, он стал очень пассивным. США отрезали российскую энергетическую поддержку евро, но не ожидали, что рубль бросит вызов базе кредитной валюты в виде физической валюты.
Хотя рубль невелик, он может стать первым темным облаком, появившимся на темном горизонте Бреттон-Вудса III (Золтан Позар, 2022).Отделение оптовых товаров от кредитного валютного ценообразования неизбежно приведет к снижению спроса на доллары США и евро. Если другие богатые ресурсами страны вместе последуют рублевой модели, спрос на доллар США может резко упасть, и в противном случае невозможный Бреттон-Вудс III может внезапно наступить, прорвав огромный пузырь доллара США. Это особенно опасно для уже сильно перевыпущенного доллара.
В условиях сегодняшней глобализации у физических валют вообще нет никаких шансов. Причина, по которой кредитная валюта может подавить традиционную физическую валюту, заключается в том, что история кредитной валюты решает проблему нехватки валюты раз и навсегда. После краха Бреттон-Вудской системы великое экономическое процветание, основанное на кредитных деньгах, заставило людей поверить, что физическая валюта была отправлена в Музей истории денег раз и навсегда.
Однако, когда валюта вступает в экономический цикл переизбытка предложения, огромный масштаб становится слабостью кредитной валюты. Особенно в условиях новой пандемии короны доллар США отказался от выдачи кредитных требований в валюте, принял MMT без какой-либо корреспонденции по активам и напрямую выдал деньги резидентам. Модель напрямую вызвала большую инфляцию, которой не было бы в исходном кредите на выпуск валюты. До сих пор годовые темпы роста ИПЦ, которые Федеральная резервная система считает временным явлением, достигали или превышали 5% в течение одиннадцати месяцев подряд.
После начала российско-украинской войны инфляция в США не ослабевает. 12 апреля Бюро статистики труда США опубликовало данные, показывающие, что индекс потребительских цен США вырос на 8,5% в годовом исчислении в марте, опередив предыдущее значение в 7,9%, которое также было выше ожиданий рынка в 8,4%, что является самым быстрым темпом роста с декабря 1981 года. Если российско-украинский конфликт продолжит подталкивать вверх цены на энергоносители и продовольствие, доллару США и евро придется повысить процентные ставки.
На самом деле рынок уже отреагировал на эту перспективу доллара США. 11 апреля доходность 20-летних казначейских облигаций США сильно выросла примерно на 9 базисных пунктов до 3,01%, установив самый высокий рекорд с тех пор, как Министерство финансов США возобновило выпуск 20-летних казначейских облигаций в мае 2020 года. Если процентные ставки не будут повышены, казначейские облигации США будут распроданы из-за отрицательной доходности, а если процентные ставки будут повышены, то европейские и американские рынки капитала сократятся.
В это время первоначально безнадежная физическая деноминированная валюта стала единственным ковчегом, который мог сохранить богатство во время великого потопа. Поэтому, даже если прогресс России на первом поле боя будет неблагоприятным, пока российско-украинская война может втянуть мировую экономику в серьезный спад, физически деноминированная российская экономика может выжить до конца на втором поле боя. Даже подобно Советскому Союзу в первой пятилетке, не задумываясь скопировать активы развитых стран и завершить перепрофилирование промышленности.
Попытка Соединенных Штатов обрушить российскую экономику с помощью войны может не только провалиться, но и позволить России успешно избежать грядущей Великой депрессии, как это было в бывшем Советском Союзе и Китайской Республике с серебряным стандартом. Бохайские монеты, подготовленные к выпуску базовой базой Шаньдун с материалами во время Войны Сопротивления, показали, что в условиях кредитного коллапса реальной валютой были физические объекты. Как сказал Позар: "Вы можете печатать деньги, но вы не можете печатать нефть и пшеницу”.
2. Роль Китая в шахматной игре
Хотя ВВП занимает второе место в мире, угроза Китая для экономики США гораздо меньше, чем кажется на первый взгляд. Угроза евро Соединенным Штатам глубока, а влияние Китая на Соединенные Штаты неглубоко.
Если под долларом США понимать глобализацию как "Олимпийские игры”, то евро - это “Чемпионат мира”, независимый от доллара США. Битва между Европой и Соединенными Штатами - это рыночная битва между двумя основными игроками. Так называемая “китайская угроза” происходит просто потому, что Китай выиграл слишком много медалей и слишком много говорит на “Олимпийских играх”, а сам он не представляет угрозы для “Олимпийских игр”, в которых доминирует доллар Соединенных Штатов. Чем недоволен Китай, так это американскими конкурсантами (группами производственных интересов), которые хотят обеспечить себе медали, исключив Китай из “Олимпийских игр”.
Соединенные Штаты борются с тем, что без таких игроков, как Китай, “Олимпийские игры” (доллар США) будут непривлекательными и будут заменены “Чемпионатом мира” (евро). Поэтому финансовые группы, проводящие “Олимпийские игры”, и производственные группы, участвующие в конкурсе, непоследовательно относятся к интересам Китая. Результатом компромисса между двумя сторонами является подготовка китайских конкурентов (таких как Индия и Вьетнам) и, при необходимости, исключение китайских конкурентоспособных игроков из индивидуальных соревнований. Снизить зависимость от единого продукта китайского производства и сохранить доминирование США над различными правилами (мировым порядком) “Олимпийских игр”.
Причина, по которой Соединенные Штаты внезапно обратили свой взор на Россию, заключается в том, что когда Европа и Россия используют всю мощь Соединенных Штатов для борьбы с Китаем, они вот-вот завершат экономическую интеграцию, основанную на энергетике и валюте. Как только интеграция России и Европы будет успешной, привлекательность “Чемпионата мира” (евро) может превысить привлекательность “Олимпийских игр” (долларов США), а реклама (капитал), первоначально выделенная на “Олимпийские игры” (долларов США), может переместиться на “Чемпионат мира” (евро).
Перед лицом грядущего финансового кризиса любая потеря капитала может оказаться фатальной. Это вынудило Соединенные Штаты временно свернуть клиринговый портал против Китая и ликвидировать неминуемую угрозу российско-европейской интеграции, взорвав российско-украинский конфликт. В этом вопросе у Китая и США, которые оба являются “большими золотыми медалистами” на Олимпийских играх, есть общие интересы.
Реальный мир определенно сложнее, чем Олимпиада против чемпионата мира. Но это виртуальное соревнование может лаконично изобразить роль Китая в этой игре великих держав. В этой игре великих держав китайско-американский конфликт и европейско-американский конфликт существенно отличаются друг от друга.
Независимо от того, насколько велика экономика Китая, она является частью долларовой зоны. В то время как еврозона, по-видимому, является союзником Соединенных Штатов, Соединенные Штаты совершенно ясно понимают, что евро является самой большой угрозой. Как только будет обнаружено, что евро может воспользоваться кризисом доллара, чтобы заменить его, Соединенные Штаты немедленно развернут свое оружие и сделают стратегическим приоритетом подавление евро.
По той же логике можно резонно предположить, что если российско-украинский конфликт ввергнет доллар в кризис, то можно быстро достичь урегулирования между Китаем и США. Хотя сейчас эта возможность кажется очень маленькой, она не совсем невозможна. До "Сианьского инцидента” кто бы мог подумать, что две стороны Коммунистической партии Китая смогут сотрудничать в "кровавом море ненависти"? Однако Япония начала агрессивную войну против Китая, так что это, казалось бы, крайне маловероятное событие произошло. Япония, более серьезная угроза, побудила Коммунистическую партию Китая пойти на второе сотрудничество, которого ни одна из сторон не ожидала.
Несмотря на огромные размеры экономики Китая, он далек от того, чтобы быть крупным игроком в мировой серии. Китай может выбирать, в ком участвовать, но у него еще нет возможности проводить свои собственные мероприятия. Независимо от того, сколько золотых медалей вы выиграете, вы находитесь на чужой домашней площадке. В этом отношении у нас должно быть четкое понимание. Не думайте, что ВВП превышает Европейский Союз, просто подумайте, что вы можете стать полюсом мира, потому что только обладая глобальным и незаменимым капиталом - рынками капитала (США и Европа), энергии (США и Россия), продовольствия (США и Россия), технологии (США, Япония и Европа) и т.д. - Вы можете стать глобальной валютой, и только если у вас есть глобальная валюта, кто-то будет участвовать в проводимых вами мероприятиях.
Аналитик составяющий свое заключение по неполным данным подобен игроку ставящему на число рулетки.
Взгляды отдельных авторов не обязательно отражают мою точку зрения
Гиперссылка на оригинальный материал находится в заголовке каждой статьи
Взгляды отдельных авторов не обязательно отражают мою точку зрения
Гиперссылка на оригинальный материал находится в заголовке каждой статьи
66 лет
Карма: +14.72
Регистрация: 16.11.2008
Сообщений: 4,046
Читатели: 4
Регистрация: 16.11.2008
Сообщений: 4,046
Читатели: 4

В этом плане мы даже не так хороши, как Россия, у которой по ВВП “только одна провинция Гуандун”. Россия может привязать рубль к оптовым товарам, таким как природный газ, в то время как юань может поддерживать глобальные торговые расчеты Китая только за счет резервов американской и европейской валют. Только после того, как Китай разовьет “высокие технологии", без которых не могут обойтись все страны, юань сможет стать мировой "твердой валютой”, и, возможно, тогда у Китая появится свой собственный ”дом".
Да, Китай действительно полагается на недвижимость, чтобы создать свою собственную валюту для внутренних транзакций, но это М2, генерируемые коммерческими банками. Поскольку нет глобальной ликвидности для недвижимости, нет и жесткого зарубежного спроса на китайскую недвижимость, что определяет, что только базовая валюта, подготовленная центральным банком через резерв доллара США, может поддержать урегулирование внешней торговли Китая.
Отделение юаня от доллара США может серьезно повредить мировому спросу на доллар США, но это не приведет к интернационализации юаня. Если юань будет отделен от доллара США, то объем торговли Китая определенно значительно сократится, а экономика впадет в рецессию. На самом деле именно видя слабость Китая, американские производственные группы осмеливаются оказывать “крайнее давление” на Китай.
Но американские финансовые группы знают, что переговоры с Китаем на самом деле обоюдоострый меч. По сравнению с конкуренцией между Китаем и Соединенными Штатами замена евро по отношению к доллару США в международных расчетах является серьезной проблемой для Соединенных Штатов. С точки зрения Соединенных Штатов, Китай - это хроническая болезнь. Хотя это может быть хроническая болезнь, которая в конце концов убивает Соединенные Штаты, Европа - это чрезвычайная болезнь. Рост евро может сразу убить доллар.
На закрытой встрече в Индии генерал-лейтенант Шенбах, командующий военно-морским флотом Германии, выразил “согласие с российской оккупацией Крыма” и использовал “уважение к России” в обмен на свои замечания против Китая с Западом, разоблачая попытку России и Европы использовать китайско-американские отношения. конфликт для прикрытия российско-европейской интеграции. Настойчивость американской разведывательной системы в наблюдении за европейскими "союзниками" доказывает, что Соединенные Штаты нелегко обмануть.
Если Соединенные Штаты в это время отчаянно попытаются отделиться от Китая, то удар по Китаю будет не меньше удара по Соединенным Штатам. Как только огромное количество долларов США потеряет огромный спрос Китая, капитал покинет доллары США и хлынет в более безопасную Европу, защищенную российским ядерным оружием - подавляющий Китай делает свадебное платье для евро.
Из-за этого Соединенные Штаты должны заранее отрезать любую возможность российско-европейской интеграции. На самом деле именно перед лицом этой неминуемой угрозы Соединенные Штаты перенесли свой стратегический фокус с Тайваньского пролива на Украину. Пока Соединенные Штаты контролируют Европу, как бы Россия ни реформировалась, Соединенные Штаты не примут ее в западный лагерь. И как только евро потеряет свою угрозу доллару США, Китай немедленно вернется в поле зрения международных отношений США.
Интеграция России и Европы потерпела неудачу, главное - она не смогла выдержать китайско-американского противостояния. Точно так же Китай должен попытаться избежать выяснения отношений на Украине, как Россия. До тех пор, пока Россия не падет, Соединенные Штаты не смогут разрешить выяснение отношений с Китаем. Пока доллар США находится в кризисе, как единственная крупная экономика, которая может спасти доллар США, независимо от того, спасен он или нет, инициатива вернется к китайской стороне.
Действительно, в нынешней международной шахматной игре Соединенные Штаты сами выбирают, когда, с кем и где разыгрывать шоудаун. Но китайская модель борьбы с беспорядками в Гонконге показывает, что хотя Соединенные Штаты могут выбрать место, Китай может выбрать время. Пока она тянется до тех пор, пока другая угроза Соединенным Штатам не станет больше, чем угроза Китая, окно для китайско-американского сотрудничества снова откроется. Эта угроза - грядущий долларовый кризис.
Никто не знает, когда состоится следующая “дипломатия пинг-понга”, но пока долларовый кризис существует для Соединенных Штатов, Китай и Соединенные Штаты могут снова принять решение о сотрудничестве. Степень, в которой сотрудничество может быть восстановлено, зависит от степени ущерба, нанесенного Соединенным Штатам этим кризисом.
Перед лицом серьезных изменений, которые не наблюдались уже сто лет, Китай должен иметь стратегическую решимость дождаться (или даже внести свой вклад) предстоящего кризиса баланса доллара США. В это время наступательная и оборонительная позиции Китая и США поменяются позициями, и можно будет обменяться интересами с Соединенными Штатами - в обмен на поддержку доллара США (покупку американского долга) в обмен на отмену санкций в отношении китайского производства, особенно высокотехнологичного. Успех реагирования на беспорядки в Гонконге показывает, что “окончательная победа часто заключается в настойчивых усилиях.”
3. Китай: Хэчжун или Лянь Сюн?
Избегание войны не равнозначно страху перед войной. Только будучи готовым противостоять худшим результатам, худшее может случиться. Каждая санкция США против России и ее последствия, каждый шаг, на который Россия реагирует, достойны повторного анализа и анализа стратегии Китая.
Российско-украинская война может рассматриваться нами как ценная огневая разведка, и каждый огневой пункт, с которым Соединенные Штаты будут иметь дело с Китаем в будущем, будет подвергаться нашему наблюдению. Многие санкции, которые мы считаем фатальными, на самом деле имеют ограниченное действие, в то время как некоторые инструменты, которые мы думали, что никогда раньше не будем использовать, используются для санкций без колебаний.
Например, ранее знакомая модель доллара США, использующая ослабление и ужесточение для сбора урожая на оффшорных рынках капитала, была модернизирована до сбора урожая непосредственно на оншорном рынке во время этого кризиса. После начала российско-украинского конфликта британский орган финансового регулирования выпустил уведомление с просьбой к инвесторам продавать российские акции, в противном случае биржа принудительно продаст акции от вашего имени.
Если взять в качестве примера Сбербанк Российской Федерации, то цена закрытия до начала конфликта составляла 88,97 доллара США, а через 6 торговых дней цена закрытия составила всего 00,52 доллара США, то есть падение составило 95%.Так кто же покупатель? 5 марта агентство Bloomberg сообщило, что только финансовые хищники Уолл-стрит в США - Goldman Sachs и JP Morgan Chase - имеют право покупать.
China General stocks концентрирует почти все самые качественные промышленные активы Китая, которые намного больше российских. Если доллар попадет в кризис, который нельзя будет спасти обычными средствами, Соединенные Штаты могут напрямую собирать богатства других стран непосредственно на внутреннем рынке. Такой подход, который раньше был немыслим, теперь, по-видимому, полностью свободен от препятствий.
Если не будет создан механизм долгосрочной юрисдикции для соблюдения офшорных сделок, все богатство Китая на зарубежных рынках капитала не будет в безопасности. Можем ли мы использовать платформу евро в качестве альтернативы платформе доллара США? Российско-украинская война заставила мир ясно увидеть, что евро ненадежен в критический момент. Европа столь же беспринципна в расхищении богатств.
Если Европа не примет Россию в систему евро, а Соединенные Штаты также вытеснят Китай из долларовой системы, то самый маловероятный сценарий привязки юаня к российской энергетике станет последним выбором для Китая и России. Российский рубль привязан к энергетике, и, по сути, Россия, которая была изгнана из двух крупных событий, открыла еще одно событие.
Появление рубля, привязанного к физическим объектам (энергия, золото), не только обеспечивает канал-убежище для кредитных валют, избегающих высоких ценовых рисков, но и выкапывает кредитные валюты (доллары), которые уже находятся на грани дефицита и избытка ./EUR) для большого куска спроса.
Но чтобы конкурировать с долларом США и евро, рубль все еще нуждается в поддержке огромного рынка энергопотребления. Если потребности Китая сочетаются с ресурсами России, то можно обеспечить мир более безопасным инструментом хранения богатства, когда наступит Великая депрессия. Исходя из этого, необходимо как можно скорее создать внутреннюю систему валютных расчетов “БРИКС + Шанхайская организация сотрудничества”, в которой Бразилия, Иран и Россия являются крупными продовольственными и энергетическими странами, а Китай, Индия и ЮАР - крупными потребителями Хотя эта система не может полностью заменить Глобальную банковскую, финансовую и телекоммуникационную ассоциацию (SWIFT), необходимо как можно скорее создать внутреннюю систему валютных расчетов "БРИКС + Шанхайская организация сотрудничества".) Платежная система, но, по крайней мере, она может заставить Запад дважды подумать, когда это превращает его в оружие.

Курс японской иены по отношению к доллару США достиг 20-летнего минимума. Источник изображения: Vision China
28 марта 2022 года Бруно Масайнш, обозреватель газеты The New Statesman, взял интервью у Сергея Караганова, почетного председателя “Комитета по внешней и оборонной политике” московского аналитического центра и советника бывшего президента.
Когда его спросили, беспокоится ли он о том, что Россия, изолированная Западом, будет уязвима для китайского экономического влияния, он ответил: "Китай обладает большей частью необходимых нам технологий, и у него много капитала......Поэтому я не боюсь, что Россия станет частью великого Китая. Еще одна причина, по которой я не боюсь, заключается в том, что китайская цивилизация совсем другая. У нас в генах есть азиатские черты, так что в какой-то степени мы азиатская страна.”
Речь Сергея Караганова, возможно, была направлена на то, чтобы использовать перспективу китайско-российской интеграции для угрозы Европе и Соединенным Штатам, которые сжимают стратегическое пространство России. Но, по крайней мере, это также показывает, что российская элита начала всерьез рассматривать возможность такого сочетания китайско-российского альянса. В конце концов, стратегия - это игра, а не азартная игра. Стратегия не может основываться на угадывании поведения противника, а на полной готовности ко всем возможным сценариям.
Хотя Китаю и России требуется более глубокое взаимное доверие для достижения высокого уровня интеграции, подобного Европейскому Союзу, просто изучая возможность такого альянса, санкции против Запада являются сдерживающим фактором - только когда противник поймет, что санкции неэффективны, настоящих санкций не будет.
В конечном счете, вы сами должны справиться с великими переменами, которых не было видно уже сто лет. Соединенные Штаты однажды ввели всеобъемлющие санкции против Китая в 1989 году. Способность Китая успешно "противостоять окружению" во многом зависит от быстрого развития китайского рынка - двузначного роста экономики, рынка, от которого не может отказаться ни один капитал.
В будущем, если Китай хочет противостоять давлению внешних санкций, он все равно должен рассчитывать на быстрое экономическое развитие. В настоящее время существует поговорка, которая противопоставляет высокую скорость высокому качеству, не понимая, что любое замедление роста Китая снизит способность Китая реагировать на внешние санкции. Без огромного рынка Китай был бы Северной Кореей и Кубой, и даже Иран и Ирак не смогли бы этого сделать.
Валютные войны, как и все войны, могут длиться до тех пор, пока экономика противника не рухнет, прежде чем партия сможет спасти свое собственное богатство и получить возможность собрать богатство противника.
Второе поле битвы России и Украины продемонстрировало решающую роль мощного рынка капитала в войне. Нынешняя битва за защиту рынка недвижимости имеет глобальное значение для того, сможет ли Китай до конца продержаться на втором поле битвы в будущем.
Хотя выводы и предложения этой статьи спорны, очень важно проанализировать битву между Россией и Украиной с точки зрения валюты. Если привязка рубля к энергоносителям рассматривается как “валютное восстание”, независимо от его успеха или неудачи, то это очень ценный практический пример для других валют, которые могут столкнуться с санкциями доллара США.
Через много лет мы можем обнаружить, что сегодняшние российско-украинские бои на втором поле боя оказывают не меньшее влияние на мировую картину, чем на первом поле боя. Даже сама Третья мировая война может быть валютной войной, а "ресурсный рубль" - лишь пролог к этой войне.
Аналитик составяющий свое заключение по неполным данным подобен игроку ставящему на число рулетки.
Взгляды отдельных авторов не обязательно отражают мою точку зрения
Гиперссылка на оригинальный материал находится в заголовке каждой статьи
Взгляды отдельных авторов не обязательно отражают мою точку зрения
Гиперссылка на оригинальный материал находится в заголовке каждой статьи
66 лет
Карма: +14.72
Регистрация: 16.11.2008
Сообщений: 4,046
Читатели: 4
Регистрация: 16.11.2008
Сообщений: 4,046
Читатели: 4
"Возвращение в средневековье" – Если Россия сократит поставки газа, Чехия может оказаться в серьезной беде
Статья 174 0
"Возвращение в средневековье" – Если Россия сократит поставки газа, Чехия может оказаться в серьезной бедеСтатья 174 0
Чехия на 98 процентов зависит от российского газа, а это значит, что любое сокращение может быть катастрофическим
ДЖОН КОДИ
28 апреля 2022 года

Существуют разные оценки последствий сокращения поставок российского газа в Чехию, но поскольку страна получает почти весь свой газ из России, результаты могут быть ужасными.
"Когда кто-то говорит закрыть клапаны с российским газом, они понятия не имеют, о чем говорят. Я никому не желаю возвращения в средневековье ", - заявил бывший премьер-министр Мирек Тополанек,
По словам Тополанека, Чехия не сможет быстро компенсировать российский газ. Чехия на 98 процентов зависит от российского газа, по сравнению с 31 процентом для Польши. Таким образом, последствия прекращения Россией поставок будут разрушительными как для домашних хозяйств, так и для бизнеса. По мнению Тополанека, Чехия также не может зависеть от Германии или стран Юго-восточной Европы, поскольку те должны будут в первую очередь покрыть свои потребности.
"Экономика войны" – сокращение поставок российского газа может привести к массовому закрытию европейских заводов и компаний, считает чешский аналитик
Европа не может найти адекватную замену российскому газу в этом году и должна будет перейти к военной экономике, утверждает чешский аналитик Иржи Гавор
Нынешний премьер-министр Чехии Петер Фиала предлагает несколько более оптимистичный прогноз, заявив вчера, что если Россия прекратит поставки газа в Чехию, страна будет управлять ситуацией в течение некоторого времени, но затем потребуется помощь со стороны Европейского Союза, сообщает чешское новостное издание Idnes.
"Мы можем справиться с этим в течение некоторого времени, объединив резервы и других поставщиков. Но в долгосрочной перспективе мы должны искать другие решения ”, - сказал Фиала.
Фиала упомянул альтернативные источники газа, альтернативных поставщиков, сжиженный газ и терминалы СПГ в качестве возможных непредвиденных обстоятельств, чтобы смягчить последствия любого отключения от российского газа. Соединенные Штаты пообещали увеличить поставки СПГ как в этом, так и в следующем году, однако такой СПГ является дорогостоящим и сложным в транспортировке.
До сих пор у чешского правительства не было никакой информации или сигнала о том, что Россия может отрезать Чехию от поставок газа, как это произошло с Польшей и Болгарией ранее на этой неделе.
“Мы предпринимаем шаги, которые должны обеспечить граждан Чехии достаточным количеством энергии из всех возможных источников, если Россия продолжит свои действия”, - заверил Фиала в Палате депутатов.
Фиала сказал, что считает Россию ненадежным поставщиком энергии, что делает поиск альтернатив необходимостью для Чехии и всего Европейского Союза. Премьер-министр также раскритиковал предыдущие администрации за то, что они не сделали достаточно для достижения лучшей энергетической безопасности страны.
Аналитик составяющий свое заключение по неполным данным подобен игроку ставящему на число рулетки.
Взгляды отдельных авторов не обязательно отражают мою точку зрения
Гиперссылка на оригинальный материал находится в заголовке каждой статьи
Взгляды отдельных авторов не обязательно отражают мою точку зрения
Гиперссылка на оригинальный материал находится в заголовке каждой статьи
66 лет
Карма: +14.72
Регистрация: 16.11.2008
Сообщений: 4,046
Читатели: 4
Регистрация: 16.11.2008
Сообщений: 4,046
Читатели: 4
Переходят ли США от стагфляции непосредственно к полномасштабной экономической депрессии?
Статья 156 0
Переходят ли США от стагфляции непосредственно к полномасштабной экономической депрессии?Статья 156 0
Майкл Снайдер
28 апреля 2022 года

Должен ли тот факт, что экономика США фактически сократилась в течение первого квартала, действительно удивить кого-либо из нас? С начала 2022 года кризис сменялся кризисом, и теперь война в Украине угнетает экономическую активность по всей планете. То, с чем мы сталкиваемся, можно определенно описать как “идеальный шторм” и правда в том, что этот шторм не собирается уходить в ближайшее время. Но куда мы идем отсюда? Восстановится ли экономика США, или этот новый экономический спад вскоре станет еще хуже? Большинство экономических оптимистов предполагают, что первое будет правдой, в то время как многие экономические реалисты выпускают страшные предупреждения о том, что впереди.
На самом деле я думал написать сегодня о чем-то другом, но я знал, что мои постоянные читатели захотят, чтобы я рассказал об этом…
Валовой внутренний продукт неожиданно снизился на 1,4% в годовом исчислении в первом квартале, ознаменовав резкий разворот экономики, демонстрирующей лучшие показатели с 1984 года, сообщило Министерство торговли в четверг.
Отрицательные темпы роста пропустили даже приглушенную оценку Dow Jones о росте на 1% за квартал, но первоначальная оценка для Q1 была худшей со времен вызванной пандемией рецессии в 2020 году.
Мы уже знали, что инфляция в Соединенных Штатах начала выходить из-под контроля, и теперь наступила “оленья” часть “стагфляции”.
Так что же вызвало этот “внезапный” спад? По данным CNN, есть довольно много факторов, которые можно обвинить…
Толчок Федеральной резервной системы к повышению процентных ставок и борьбе с высокой инфляцией. Дефицит цепочки поставок. Продолжающийся глобальный кризис здравоохранения. И, конечно, геополитическое землетрясение, вызванное вторжением России на Украину, которое также угрожает создать мировой продовольственный кризис.
Если экономика США снова сократится во втором квартале, это официально будет соответствовать определению “рецессии”.
Но как отметил Джон Уильямс из shadowstats.com , что если бы использовались честные цифры, то экономика США все еще находилась бы в состоянии рецессии, которая началась еще в начале пандемии КОВИДА.
Все в значительной степени понимают, что экономические условия сейчас не очень хороши.
Так что яркие дни не за горами? Именно так, кажется, думают некоторые ученые мужи…
Экономика США вернется к росту во втором квартале, считает главный экономист RSM Джо Брусуэлас. “Без сомнения”, - сказал он.
“Это шум, а не сигнал”, - написал в своем докладе главный экономист Pantheon Macroeconomics Ян Шепердсон. “Экономика не впадает в рецессию”.
Может быть, они будут правы.
Но если экономика так сильна, то почему количество заявок на выкуп жилья стремительно растет?…
В прошлом месяце 33 333 объекта недвижимости в США столкнулись с потерей права выкупа, что на 181 процент больше, чем в марте 2021 года, и на 29 процентов больше, чем в феврале, согласно отчету трекера выкупа Attom. В первом квартале было зарегистрировано 78 271 недвижимость, что на 39 процентов больше, чем в предыдущем квартале, и на 132 процента больше, чем в прошлом году.
Излишне говорить, что есть и другие эксперты, которые гораздо более негативно оценивают то, что нас ждет впереди.
Например, Нэнси Лазар предупреждает о “синхронизированной” глобальной рецессии…
Главный глобальный экономист Piper Sandler Нэнси Лазар предупредила в понедельник, что мир находится на ранних стадиях «очень значительной» и «синхронной» рецессии.
В понедельник, выступая в программе “Утро с Марией”, Лазар отметила, что рецессия ожидается за пределами Соединенных Штатов.
“Это будет глобальная рецессия, которая потянет вниз [еврозону], в частности”, - сказала она ведущей Марии Бартиромо. “Похоже, что ВВП Китая [валовой внутренний продукт] во втором квартале также может быть отрицательным”.
На самом деле, если все, что мы пострадаем, это значительная глобальная рецессия, которая будет действительно хорошей новостью.
Поскольку именно в этот момент инфляция резко возрастает по всему миру, мы являемся свидетелями крупнейшей сухопутной войны в Европе со времен Второй мировой войны, и ООН говорит нам, что мы приближаемся к ужасающему мировому продовольственному кризису.
Все большее число американцев начинают понимать, что все движется в неправильном направлении. В апрельском опросе Гэллапа только 18 процентов американцев оценили экономические условия как “хорошие”, и только 2 процента оценили их как “отличные”.…
Новости о ВВП следуют за недавно опубликованными данными опроса Gallup, которые показали, что доверие к экономике среди американской общественности крайне низкое.
Более четырех из десяти (42%) американцев заявили, что экономические условия в Америке были “плохими”, в то время как еще 38% сказали, что они были только “справедливыми” в апрельском опросе Гэллапа. Только 2% сказали, что экономические условия были “превосходными”, в то время как 18% сказали, что они были “хорошими”.
Это ужасные цифры, и они имеют очень серьезные последствия для демократов осенью.
Но вместо того, чтобы сосредоточиться на восстановлении экономики, Джо Байден хочет, чтобы Конгресс выделил ему еще 33 миллиарда долларов на войну в Украине…
Президент Джо Байден просит Конгресс выделить еще 33 миллиарда долларов, чтобы помочь Украине противостоять вторжению России и предоставить гуманитарную помощь украинскому народу.
Предложение, которое Белый дом направит законодателям в четверг, включает в себя $ 20 млрд дополнительной помощи в области безопасности и военной помощи Украине, еще $ 8 млрд - экономической помощи и $ 3 млрд - гуманитарной помощи.
Это полное и полное безумие.
Чтобы представить это в перспективе, военный бюджет Украины обычно составляет около 6 миллиардов долларов в течение всего года.
И большая часть оборудования, которое США отправляют в Украину, взрывается русскими еще до того, как оно попадает к бойцам на передовой.
С каждым днем всем становится все яснее, что этот конфликт на самом деле является опосредованной войной между Соединенными Штатами и Россией.
А ядерная война все чаще становится одной из самых горячих тем на российском телевидении. Например, ниже приводится недавний обмен мнениями между двумя российскими телевизионщиками, который попал в заголовки газет по всему миру…
“Все закончится ядерным ударом более вероятно, чем другой исход”, - продолжила она. “Это к моему ужасу, с одной стороны, но с другой стороны, с пониманием того, что это то, что есть”.
Именно в этот момент Соловьев вмешался: “Но мы попадем в рай, а они просто сдохнут”.
“Мы все когда-нибудь умрем”, - согласилась Симонян.
“Мы все когда-нибудь умрем”?
Мне, конечно, не нравится, как это звучит.
К сожалению, многие россияне сейчас полностью убеждены в том, что грядет ядерная война.
Но вместо того, чтобы настаивать на мире, Джо Байден и его приспешники просто продолжают эскалацию конфликта.
Если мы продолжим идти по этому пути, это закончится кошмаром.
Наши текущие экономические проблемы бледнеют по сравнению с возможностью ядерного конфликта, но большинство американцев все еще не понимают последствий решений, которые принимают наши лидеры.
Потому что, если бы они поняли, на улицах каждого крупного города США прямо сейчас были бы гигантские протесты.
Аналитик составяющий свое заключение по неполным данным подобен игроку ставящему на число рулетки.
Взгляды отдельных авторов не обязательно отражают мою точку зрения
Гиперссылка на оригинальный материал находится в заголовке каждой статьи
Взгляды отдельных авторов не обязательно отражают мою точку зрения
Гиперссылка на оригинальный материал находится в заголовке каждой статьи
66 лет
Карма: +14.72
Регистрация: 16.11.2008
Сообщений: 4,046
Читатели: 4
Регистрация: 16.11.2008
Сообщений: 4,046
Читатели: 4
Запад ввел общественность в заблуждение относительно военной стратегии России, и результаты начинают проявляться на Донбассе
The Silksworth Post
28 апреля 2022

Если вы следите за освещением войны в Украине в западных СМИ, вы, вероятно, придете к одному четкому выводу: для России все идет не по плану. Если вы встроены в мир Twitter, вы, вероятно, даже подумаете, что Москва проигрывает. Есть достаточно оснований принимать это за чистую монету: очевидный план оккупации Киева и севера страны, казалось бы, провалился, что привело к выводу сил России, в то время как силы Путина, похоже, понесли больше ожидаемых потерь, а черноморский флагман "Москва" был потоплен. Это сочетается с репортажами, которые неоднократно предполагают, что Путин стремился к тому, чтобы война была быстрой, короткой и безболезненной, изображая его просчитавшимся, умственно деградирующим и попадающим в трясину, которую он сам создал.
За исключением того, что это не так. Хотя действительно верно, что войны никогда не идут по плану и всегда преодолевают непредвиденные издержки, тем не менее также является реальностью, что освещение конфликта западными СМИ было не чем иным, как вопиющей военной пропагандой и кампанией психологической войны, которая совпала с преднамеренной кампанией по цензуре другой стороны истории конфликта. В конечном счете нелепо предполагать, что СМИ могут даже подумать о том, чтобы быть беспристрастными, когда, учитывая серьезность конфликта, они находятся под огромным социальным и политическим давлением, чтобы “принять сторону” и облачить в то, что они надеются, будет надвигающейся неудачей Путина.
И в результате неудивительно, что на самом деле все идет не так плохо для России, как людям говорили. Ситуация на Востоке Украины сейчас находится на критическом этапе. Россия консолидировала огромный выступ, нависающий над Донецкой областью из города Изюм, создавая карман, подобный заливу, вокруг украинских сил под ним, которые также сталкиваются с российскими силами, вытесняющими из Луганска. Между тем, русские одновременно начали продвигаться из Запорожской области, надеясь в конечном итоге обойти укрепленную линию украинских солдат за пределами Донецка. Цель? Перекрывающаяся атака клещей и двустороннее окружение с севера и юга. Если Москва преуспеет в своих целях, огромная часть всей армии Украины окажется в ловушке в этом возникающем кармане.

Отредактированная карта Википедии о ситуации на Донбассе
География благоприятствует русскому наступлению. Российские позиции в этом районе укреплены, защищены и находятся далеко за пределами досягаемости Украины, что не позволяет им проводить контрнаступления, подобные тем, которые они проводили против российских войск на севере страны. Это позволяет Москве постоянно получать дополнительные выгоды, не страдая от крупномасштабных потерь, признак того, что они избежали тех же ошибок, которые они ранее совершили в войне. Не только это, но и их позиционирование означает, что они эффективно наступают на Украину со всех направлений, лишая украинскую армию возможности концентрировать силы в одном районе, как это было ранее в отношении уязвимых российских линий снабжения. Это было связано с усилиями Русских по подавлению их артиллерийским огнем.
События в Донбассе, по-видимому, застали врасплох видных западных военных аналитиков, которые в остальном поспешили подтвердить неизбежный провал России. Институт изучения войны (ISW), известный пессимист, был вынужден признать 27 апреля, что Россия реализует “более разумную модель оперативного движения” в Донбассе, и даже был вынужден признать, что украинская оборона на севере региона дезорганизована. Хотя ISW продолжает утверждать, что более широкого российского окружения украинской армии не произойдет. Трудно понять, как Украина собирается переломить ситуацию в этой ситуации даже при поддержке Запада, потому что у них просто нет географического преимущества. Россия набирает обороты в регионе каждый божий день.
Это говорит о стратегии России. Когда Москва объявила, что уходит с Севера и сосредотачивается на Донбассе, это было продано как отступление и провал, но при ближайшем рассмотрении оказалось, что нападение на этот регион было тщательно спланировано в логической последовательности подготовительных шагов. Появляется все больше свидетельств того, что Россия использовала предыдущие этапы войны, чтобы подготовить стратегическую почву для этого. Некоторые люди могли бы спросить: почему Москва просто не ворвалась в Донбасс сразу? И вроде бы пошли на Киев? И это хороший вопрос, и ответ заключается в том, что при самой высокой концентрации там украинских сил, «их наиболее подготовленных войск», что часто ускользает, у России не было бы преимуществ на поле боя или позиций, чтобы отбросить их назад, что они имеют сейчас.
Прежде чем Россия приступила к своему нынешнему наступлению на Донбасс, она сначала предприняла процесс “формирования поля боя”. что предполагало отвлечение Украины путем вторжения на Север страны (даже если была надежда на быстрое окружение Киева). Когда эти "оси" были открыты, Россия затем вторглась из Крыма и захватила Херсонскую область (чтобы предотвратить упреждающее нападение Украины на полуостров) и продвинулась в Запорожье (создав южную стартовую площадку). Мариуполь был тогда окружен и отрезан. Эти многочисленные открытые фронты позволили России вторгнуться в Харьковскую и Луганскую области, которые они затем превратили в Северный фланг с захватом Изюма.
Стоит отметить, что ни на одном этапе этого Россия не пыталась штурмовать укрепленные линии Украины, окружающие район Донецка, район, который был наиболее боеспособным и долгосрочно готовым к нападению. Эта область остается относительно неизменной на протяжении всей войны. Вместо этого более широкая картина заключалась в том, чтобы обойти их с тыла как с севера, так и с юга с целью стратегического окружения. Совершенно очевидно, что Россия рассматривает эти усилия как определяющую битву и момент войны, и, конечно, Запад тоже, но это не то, что они сказали своей общественности. Они ввели людей в заблуждение, что эти подготовительные этапы были на самом деле не более чем прерванной операцией по быстрому захвату всей страны и сместили цели от реальности, что Донбасс всегда был одним из самых больших призов.
Кажется ужасно странным, что для страны, которая “побеждает”, запад теперь серьезно повышает свою военную помощь, а также свою риторику в ожидании, что они могут заставить Путина потерпеть неудачу, но мало кто знает, что это потому, что прилив на поле боя начинает поворачиваться против них. Россия понесла много непредвиденных потерь и сопротивления на этом пути, но повествование о том, что они проигрывают войну и сталкиваются с поражением, ослабевает. Реальность начинает приходить. Запад ведет Киев с края обрыва, пытаясь спровоцировать его на более глубокую войну, и высокомерие, проявленное в недавней речи Лиз Трасс, свидетельствует о том, что именно они с большей вероятностью потерпят политический провал, чем сам Путин.
The Silksworth Post
28 апреля 2022
Если вы следите за освещением войны в Украине в западных СМИ, вы, вероятно, придете к одному четкому выводу: для России все идет не по плану. Если вы встроены в мир Twitter, вы, вероятно, даже подумаете, что Москва проигрывает. Есть достаточно оснований принимать это за чистую монету: очевидный план оккупации Киева и севера страны, казалось бы, провалился, что привело к выводу сил России, в то время как силы Путина, похоже, понесли больше ожидаемых потерь, а черноморский флагман "Москва" был потоплен. Это сочетается с репортажами, которые неоднократно предполагают, что Путин стремился к тому, чтобы война была быстрой, короткой и безболезненной, изображая его просчитавшимся, умственно деградирующим и попадающим в трясину, которую он сам создал.
За исключением того, что это не так. Хотя действительно верно, что войны никогда не идут по плану и всегда преодолевают непредвиденные издержки, тем не менее также является реальностью, что освещение конфликта западными СМИ было не чем иным, как вопиющей военной пропагандой и кампанией психологической войны, которая совпала с преднамеренной кампанией по цензуре другой стороны истории конфликта. В конечном счете нелепо предполагать, что СМИ могут даже подумать о том, чтобы быть беспристрастными, когда, учитывая серьезность конфликта, они находятся под огромным социальным и политическим давлением, чтобы “принять сторону” и облачить в то, что они надеются, будет надвигающейся неудачей Путина.
И в результате неудивительно, что на самом деле все идет не так плохо для России, как людям говорили. Ситуация на Востоке Украины сейчас находится на критическом этапе. Россия консолидировала огромный выступ, нависающий над Донецкой областью из города Изюм, создавая карман, подобный заливу, вокруг украинских сил под ним, которые также сталкиваются с российскими силами, вытесняющими из Луганска. Между тем, русские одновременно начали продвигаться из Запорожской области, надеясь в конечном итоге обойти укрепленную линию украинских солдат за пределами Донецка. Цель? Перекрывающаяся атака клещей и двустороннее окружение с севера и юга. Если Москва преуспеет в своих целях, огромная часть всей армии Украины окажется в ловушке в этом возникающем кармане.
Отредактированная карта Википедии о ситуации на Донбассе
География благоприятствует русскому наступлению. Российские позиции в этом районе укреплены, защищены и находятся далеко за пределами досягаемости Украины, что не позволяет им проводить контрнаступления, подобные тем, которые они проводили против российских войск на севере страны. Это позволяет Москве постоянно получать дополнительные выгоды, не страдая от крупномасштабных потерь, признак того, что они избежали тех же ошибок, которые они ранее совершили в войне. Не только это, но и их позиционирование означает, что они эффективно наступают на Украину со всех направлений, лишая украинскую армию возможности концентрировать силы в одном районе, как это было ранее в отношении уязвимых российских линий снабжения. Это было связано с усилиями Русских по подавлению их артиллерийским огнем.
События в Донбассе, по-видимому, застали врасплох видных западных военных аналитиков, которые в остальном поспешили подтвердить неизбежный провал России. Институт изучения войны (ISW), известный пессимист, был вынужден признать 27 апреля, что Россия реализует “более разумную модель оперативного движения” в Донбассе, и даже был вынужден признать, что украинская оборона на севере региона дезорганизована. Хотя ISW продолжает утверждать, что более широкого российского окружения украинской армии не произойдет. Трудно понять, как Украина собирается переломить ситуацию в этой ситуации даже при поддержке Запада, потому что у них просто нет географического преимущества. Россия набирает обороты в регионе каждый божий день.
Это говорит о стратегии России. Когда Москва объявила, что уходит с Севера и сосредотачивается на Донбассе, это было продано как отступление и провал, но при ближайшем рассмотрении оказалось, что нападение на этот регион было тщательно спланировано в логической последовательности подготовительных шагов. Появляется все больше свидетельств того, что Россия использовала предыдущие этапы войны, чтобы подготовить стратегическую почву для этого. Некоторые люди могли бы спросить: почему Москва просто не ворвалась в Донбасс сразу? И вроде бы пошли на Киев? И это хороший вопрос, и ответ заключается в том, что при самой высокой концентрации там украинских сил, «их наиболее подготовленных войск», что часто ускользает, у России не было бы преимуществ на поле боя или позиций, чтобы отбросить их назад, что они имеют сейчас.
Прежде чем Россия приступила к своему нынешнему наступлению на Донбасс, она сначала предприняла процесс “формирования поля боя”. что предполагало отвлечение Украины путем вторжения на Север страны (даже если была надежда на быстрое окружение Киева). Когда эти "оси" были открыты, Россия затем вторглась из Крыма и захватила Херсонскую область (чтобы предотвратить упреждающее нападение Украины на полуостров) и продвинулась в Запорожье (создав южную стартовую площадку). Мариуполь был тогда окружен и отрезан. Эти многочисленные открытые фронты позволили России вторгнуться в Харьковскую и Луганскую области, которые они затем превратили в Северный фланг с захватом Изюма.
Стоит отметить, что ни на одном этапе этого Россия не пыталась штурмовать укрепленные линии Украины, окружающие район Донецка, район, который был наиболее боеспособным и долгосрочно готовым к нападению. Эта область остается относительно неизменной на протяжении всей войны. Вместо этого более широкая картина заключалась в том, чтобы обойти их с тыла как с севера, так и с юга с целью стратегического окружения. Совершенно очевидно, что Россия рассматривает эти усилия как определяющую битву и момент войны, и, конечно, Запад тоже, но это не то, что они сказали своей общественности. Они ввели людей в заблуждение, что эти подготовительные этапы были на самом деле не более чем прерванной операцией по быстрому захвату всей страны и сместили цели от реальности, что Донбасс всегда был одним из самых больших призов.
Кажется ужасно странным, что для страны, которая “побеждает”, запад теперь серьезно повышает свою военную помощь, а также свою риторику в ожидании, что они могут заставить Путина потерпеть неудачу, но мало кто знает, что это потому, что прилив на поле боя начинает поворачиваться против них. Россия понесла много непредвиденных потерь и сопротивления на этом пути, но повествование о том, что они проигрывают войну и сталкиваются с поражением, ослабевает. Реальность начинает приходить. Запад ведет Киев с края обрыва, пытаясь спровоцировать его на более глубокую войну, и высокомерие, проявленное в недавней речи Лиз Трасс, свидетельствует о том, что именно они с большей вероятностью потерпят политический провал, чем сам Путин.
Аналитик составяющий свое заключение по неполным данным подобен игроку ставящему на число рулетки.
Взгляды отдельных авторов не обязательно отражают мою точку зрения
Гиперссылка на оригинальный материал находится в заголовке каждой статьи
Взгляды отдельных авторов не обязательно отражают мою точку зрения
Гиперссылка на оригинальный материал находится в заголовке каждой статьи
66 лет
Карма: +14.72
Регистрация: 16.11.2008
Сообщений: 4,046
Читатели: 4
Регистрация: 16.11.2008
Сообщений: 4,046
Читатели: 4
Польша угрожает захватить российские трубопроводы
Чарльз Кеннеди
29 апреля 2022 года,

Премьер-министр Польши Матеуш Моравецкий выступает перед СМИ на АЗС Gaz-System в Рембельщизне, недалеко от Варшавы, Польша, среда, 27 апреля 2022 года. Польские и болгарские лидеры обвинили Москву в использовании природного газа для шантажа своих стран после того, как российская государственная энергетическая компания прекратила поставки двух европейских стран в среду. (AP Photo / Czarek Sokolowski) Associated Press
Associated Press
Поскольку Польша отчаянно пытается восстановить подачу российского газа в страну, ее правительство приказало российскому «Новатэку» передать трубопроводную инфраструктуру или предстать перед судом, равносильным экспроприации инфраструктуры.
В пятницу представитель польского правительства сообщил агентству Ассошиэйтед Пресс, что российскому Новатэку Green Energy было приказано предоставить свои трубопроводы польским компаниям и что невыполнение этого требования будет означать судебный иск.
Ссылаясь на законы о кризисном управлении, AP процитировала представителя правительства Петра Мюллера, заявившего, что судьба Новатэка, второго по величине производителя природного газа в России, “зависит от того, будет ли эта российская фирма, связанная с Россией, сотрудничать должным образом ... не будут ли сотрудники, действуя по каким-то указаниям, пытаться каким-то образом заблокировать этот процесс”.
Российские СМИ RT, рупор Кремля, сообщили, что премьер-министр Польши Матеуш Моравецкий “попросил государственные компании PGNiG, PSG и Gaz-System немедленно поставлять газ в сети, формально принадлежащие Новатэку”.
В то время как государственные газовые компании Польши могут обеспечить газом те муниципалитеты, которые были отрезаны, для этого им нужна инфраструктура Новатэка.
Несколько десятков польских муниципалитетов остались без газа после того, как Новатэк приостановил поставки в страну в начале этой недели.
Также ранее на этой неделе Польша включила в свой санкционный список дочернюю компанию Новатэка, а также 50 других российских и белорусских юридических и физических лиц.
В четверг польские чиновники пообещали добиться от “Газпрома” компенсации за то, что он назвал "незаконными" действиями. Польша утверждает, что Россия нарушила свой контракт, потребовав оплаты природного газа в рублях, а затем прекратив поставки газа после отказа Польши выполнить его условия.
“Газпром" должен будет выплатить нам компенсацию, потому что он действовал заведомо незаконно. Это мнение специалистов из разных стран”, - заявил польскому радио заместитель министра иностранных дел Петр Вавржик.
Чарльз Кеннеди
29 апреля 2022 года,
Премьер-министр Польши Матеуш Моравецкий выступает перед СМИ на АЗС Gaz-System в Рембельщизне, недалеко от Варшавы, Польша, среда, 27 апреля 2022 года. Польские и болгарские лидеры обвинили Москву в использовании природного газа для шантажа своих стран после того, как российская государственная энергетическая компания прекратила поставки двух европейских стран в среду. (AP Photo / Czarek Sokolowski)
Поскольку Польша отчаянно пытается восстановить подачу российского газа в страну, ее правительство приказало российскому «Новатэку» передать трубопроводную инфраструктуру или предстать перед судом, равносильным экспроприации инфраструктуры.
В пятницу представитель польского правительства сообщил агентству Ассошиэйтед Пресс, что российскому Новатэку Green Energy было приказано предоставить свои трубопроводы польским компаниям и что невыполнение этого требования будет означать судебный иск.
Ссылаясь на законы о кризисном управлении, AP процитировала представителя правительства Петра Мюллера, заявившего, что судьба Новатэка, второго по величине производителя природного газа в России, “зависит от того, будет ли эта российская фирма, связанная с Россией, сотрудничать должным образом ... не будут ли сотрудники, действуя по каким-то указаниям, пытаться каким-то образом заблокировать этот процесс”.
Российские СМИ RT, рупор Кремля, сообщили, что премьер-министр Польши Матеуш Моравецкий “попросил государственные компании PGNiG, PSG и Gaz-System немедленно поставлять газ в сети, формально принадлежащие Новатэку”.
В то время как государственные газовые компании Польши могут обеспечить газом те муниципалитеты, которые были отрезаны, для этого им нужна инфраструктура Новатэка.
Несколько десятков польских муниципалитетов остались без газа после того, как Новатэк приостановил поставки в страну в начале этой недели.
Также ранее на этой неделе Польша включила в свой санкционный список дочернюю компанию Новатэка, а также 50 других российских и белорусских юридических и физических лиц.
В четверг польские чиновники пообещали добиться от “Газпрома” компенсации за то, что он назвал "незаконными" действиями. Польша утверждает, что Россия нарушила свой контракт, потребовав оплаты природного газа в рублях, а затем прекратив поставки газа после отказа Польши выполнить его условия.
“Газпром" должен будет выплатить нам компенсацию, потому что он действовал заведомо незаконно. Это мнение специалистов из разных стран”, - заявил польскому радио заместитель министра иностранных дел Петр Вавржик.
Аналитик составяющий свое заключение по неполным данным подобен игроку ставящему на число рулетки.
Взгляды отдельных авторов не обязательно отражают мою точку зрения
Гиперссылка на оригинальный материал находится в заголовке каждой статьи
Взгляды отдельных авторов не обязательно отражают мою точку зрения
Гиперссылка на оригинальный материал находится в заголовке каждой статьи
66 лет
Карма: +14.72
Регистрация: 16.11.2008
Сообщений: 4,046
Читатели: 4
Регистрация: 16.11.2008
Сообщений: 4,046
Читатели: 4
Империя лжи жаждет получить визитную карточку мистера Сармата
Пепе Эскобар
29 апреля 2022
Единственным противоядием от пропагандистского слабоумия служат редкие голоса разума, которые, как оказалось, являются русскими, поэтому замалчиваются и / или игнорируются.
Особенно с начала GWOT (Global War on Terror) в начале тысячелетия никто никогда не терял деньги, делая ставки против токсичной комбинации высокомерия, высокомерия и невежества, последовательно развернутой Империей Хаоса и лжи.
То, что считается “анализом” в обширной интеллектуальной бесполетной зоне, известной как Страна мозговых центров США, включает в себя выдачу желаемого за действительное, как, к примеру, создание образа Пекина, “верящего”, что Москва будет играть вспомогательную роль в китайском веке только для того, чтобы увидеть Россию сейчас на геополитическом водительском сиденье.
Это пример не только откровенной русофобской/синофобской паранойи по поводу появления равных конкурентов в Евразии – первобытного англо-американского кошмара, – но и грубого невежества в тонкостях сложного российско-китайского всеобъемлющего стратегического партнерства.
Поскольку Операция Z методично реализует фазу 2, американцы – с удвоенной силой - также приступили к своей симметричной фазе 2, которая де-факто переводится как прямая эскалация в сторону Totalen Krieg, от оттенков гибридного до раскаленного, все, конечно, по доверенности. Печально известный торговец оружием Raytheon, превратившийся в главу Пентагона Ллойда Остина, отдал игру Киеву:
“Мы хотим видеть Россию ослабленной до такой степени, что она не может делать те вещи, которые она сделала, вторгшись в Украину”.
Так вот оно что: Империя хочет уничтожить Россию. Cue to War Inc. безумие безграничных оружейных грузов, спускающихся на Украину, подавляющее большинство из которых будет должным образом выпотрошено российскими точными ударами. Американцы 24/7 делятся с Киевом разведданными не только по Донбассу и Крыму, но и по российской территории. Totalen Krieg продолжает параллельно с спроектированным контролируемым разрушением экономики ЕС, а Европейская комиссия весело действует как своего рода P.R. arm НАТО.
Среди пропагандистского слабоумия и острого когнитивного диссонанса, охватившего всю сферу NATOstan, единственным противоядием служат редкие голоса разума, которые, как оказалось, являются русскими, поэтому замолкают и/или отклоняются. Запад игнорирует их на свой страх и риск.
Патрушев идет Triple-X unplugged
Начнем с выступления президента Путина на Совете законодателей в Санкт-Петербурге по случаю Дня российского парламентаризма.
Путин продемонстрировал, как едва ли новое “геополитическое оружие”, опирающееся на “русофобию и неонацистов”, вкупе с усилиями “экономического удушения” не только не смогло задушить Россию, но и внедрило в коллективное бессознательное ощущение экзистенциального конфликта - “Второй Великой Отечественной войны”.
С зашкаливающей истерией по всему спектру сообщение для Империи, которая все еще отказывается слушать и даже не понимает значения “неделимости безопасности”, должно было быть неизбежным:
“Хотел бы еще раз подчеркнуть, что если кто-то намерен вмешиваться в происходящие события извне и создает неприемлемые для России угрозы стратегического характера, он должен знать, что наши ответные удары будут молниеносными. У нас есть все инструменты для этого. Такой, какой сейчас не может похвастаться никто. И мы не будем хвастаться. Мы воспользуемся ими, если потребуется. И я хочу, чтобы об этом знали все – мы приняли все решения по этому вопросу”.
Безостановочные провокации могут привести к тому, что г-н Кинжал, г-н Циркон и г-н Сармат будут вынуждены представить свои визитные карточки в избранных западных широтах, даже без официального приглашения.
Возможно, впервые с начала операции Z Путин провел различие между военными операциями на Донбассе и остальной частью Украины. Это напрямую связано с интеграцией Херсона, Запорожья и Харькова и подразумевает, что российские Вооруженные силы будут идти и идти, устанавливая суверенитет не только в Донецкой и Луганской Народных Республиках, но и над Херсоном, Запорожьем и далее по дороге от Азовского моря до Черного Моря, вплоть до установления полного контроля над Николаевом и Одессой.
Формула предельно ясна: “Россия не может допустить создания антироссийских территорий вокруг страны”.
Теперь перейдем к чрезвычайно подробному интервью секретаря Совета Безопасности Николая Патрушева "Российской газете", где Патрушев как бы отключил triple-X.
Ключевой вывод может быть здесь: “Крах американо-ориентированного мира - это реальность, в которой нужно жить и строить оптимальную линию поведения”. “Оптимальная линия поведения” России – к большому гневу универсалистского и одностороннего гегемона – включает в себя “суверенитет, культурную и духовную идентичность и историческую память”.
Патрушев показывает, как “трагические сценарии мировых кризисов, как в прошлые годы, так и сегодня, навязываются Вашингтоном в его стремлении укрепить свою гегемонию, сопротивляясь распаду однополярного мира”. США идет на все, чтобы “добиться того, чтобы другие центры многополярного мира даже не посмели поднять головы, а наша страна не только посмела, но и публично заявила, что не будет играть по навязанным правилам”.
Патрушев не мог не подчеркнуть, как War Inc. буквально совершает убийство на Украине: “Американский и европейский военно-промышленный комплекс ликует, потому что благодаря кризису на Украине у него нет передышки от порядка. Неудивительно, что в отличие от России, заинтересованной в скорейшем завершении специальной военной операции и минимизации потерь со всех сторон, Запад полон решимости оттянуть ее хотя бы до последнего украинца”.
И это отражает психику американских элит: “Вы говорите о стране, элита которой не способна ценить чужие жизни. Американцы привыкли ходить по выжженной земле. Со времен Второй мировой войны целые города были стерты с лица земли бомбардировками, в том числе ядерными. Они затопили вьетнамские джунгли ядом, разбомбили сербов радиоактивными боеприпасами, заживо сожгли иракцев белым фосфором, помогли террористам отравить сирийцев хлором (...) Как показывает история, НАТО также никогда не было оборонительным союзом, только наступательным”.
Ранее в интервью восхитительно названному The Great Game show на российском телевидении министр иностранных дел Сергей Лавров еще раз подробно рассказал, как американцы “больше не настаивают на соблюдении международного права, а на уважении к "основанному на правилах мировому порядку’. Эти ‘правила’ никак не расшифрованы. Говорят, что сейчас мало правил. Для нас их вообще не существует. Существует международное право. Мы уважаем его, как и Устав ООН. Ключевое положение, главный принцип - суверенное равенство государств. США грубо нарушает свои обязательства по Уставу ООН, когда продвигает свои ‘правила’”.
Лаврову пришлось еще раз подчеркнуть, что нынешнюю раскаленную ситуацию можно сравнить с кубинским ракетным кризисом: “В те годы существовал канал связи, которому доверяли оба лидера. Сейчас такого канала нет. Никто не пытается его создать ”.
Империя лжи в ее нынешнем состоянии не занимается дипломатией.
Темп игры на новой шахматной доске
В тонком намеке на работу Сергея Глазьева, как объяснил в нашем недавнем интервью министр по интеграции и макроэкономике Евразийского экономического союза Патрушев попал в самое сердце нынешней геоэкономической игры, когда Россия сейчас активно движется к золотому стандарту: “Эксперты работают над предложенным научным сообществом проектом создания двухконтурной денежно-финансовой системы. В частности, предлагается определить стоимость рубля, который должен быть обеспечен как золотом, так и группой товаров, являющихся валютными ценностями, чтобы привести курс рубля в соответствие с реальным паритетом покупательной способности”.
Это было неизбежно после откровенного хищения более 300 миллиардов долларов российских валютных резервов. Возможно, Москве потребовалось несколько дней, чтобы полностью удостовериться, что она столкнулась с Totalen Krieg. Следствием этого является то, что коллективный Запад потерял всякую власть влиять на российские решения. Темп игры на новой шахматной доске задает Россия.
Ранее на этой неделе на встрече с генеральным секретарем ООН Антониу Гутеррешем Путин зашел так далеко, что заявил, что он будет более чем готов к переговорам – только с несколькими условиями: украинский нейтралитет и статус автономии для Донбасса. Но теперь все знают, что уже слишком поздно. Для Вашингтона в режиме Totalen Krieg переговоры являются анафемой - и это было так после встречи России и Украины в Стамбуле в конце марта.
До сих пор в операции Z российские вооруженные силы использовали только 12% своих солдат, 10% своих истребителей, 7% своих танков, 5% своих ракет и 4% своей артиллерии. Циферблат боли настроен на существенное повышение - и с полным освобождением Мариуполя и разрешением так или иначе котла Донбасса нет ничего, что могло бы сделать комбо истерии / пропаганды / оружия, развернутое коллективным Западом, чтобы изменить факты на местах.
Это включает в себя отчаянные гамбиты, такие как тот, который раскрыл СВР - российская внешняя разведка, которая очень редко ошибается. СВР выяснила, что ось Империя лжи / War Inc. настаивает не только на фактическом польском вторжении для аннексии Западной Украины под лозунгом “исторического воссоединения”, но и на совместном румынско-украинском вторжении в Молдову / Приднестровье, причем румынские “миротворцы” уже скапливаются рядом с границей Молдовы.
Вашингтон, как утверждает СВР, уже более месяца замышляет польский гамбит. Он будет “руководить сзади” (помните Ливию?), “поощряя” “группу стран” оккупировать Западную Украину. Итак, раздел уже на картах. Если бы это когда-нибудь материализовалось, было бы интересно поспорить, в каких местах мистер Сармат будет склонен распространять свою визитную карточку.
Пепе Эскобар
29 апреля 2022
Единственным противоядием от пропагандистского слабоумия служат редкие голоса разума, которые, как оказалось, являются русскими, поэтому замалчиваются и / или игнорируются.
Особенно с начала GWOT (Global War on Terror) в начале тысячелетия никто никогда не терял деньги, делая ставки против токсичной комбинации высокомерия, высокомерия и невежества, последовательно развернутой Империей Хаоса и лжи.
То, что считается “анализом” в обширной интеллектуальной бесполетной зоне, известной как Страна мозговых центров США, включает в себя выдачу желаемого за действительное, как, к примеру, создание образа Пекина, “верящего”, что Москва будет играть вспомогательную роль в китайском веке только для того, чтобы увидеть Россию сейчас на геополитическом водительском сиденье.
Это пример не только откровенной русофобской/синофобской паранойи по поводу появления равных конкурентов в Евразии – первобытного англо-американского кошмара, – но и грубого невежества в тонкостях сложного российско-китайского всеобъемлющего стратегического партнерства.
Поскольку Операция Z методично реализует фазу 2, американцы – с удвоенной силой - также приступили к своей симметричной фазе 2, которая де-факто переводится как прямая эскалация в сторону Totalen Krieg, от оттенков гибридного до раскаленного, все, конечно, по доверенности. Печально известный торговец оружием Raytheon, превратившийся в главу Пентагона Ллойда Остина, отдал игру Киеву:
“Мы хотим видеть Россию ослабленной до такой степени, что она не может делать те вещи, которые она сделала, вторгшись в Украину”.
Так вот оно что: Империя хочет уничтожить Россию. Cue to War Inc. безумие безграничных оружейных грузов, спускающихся на Украину, подавляющее большинство из которых будет должным образом выпотрошено российскими точными ударами. Американцы 24/7 делятся с Киевом разведданными не только по Донбассу и Крыму, но и по российской территории. Totalen Krieg продолжает параллельно с спроектированным контролируемым разрушением экономики ЕС, а Европейская комиссия весело действует как своего рода P.R. arm НАТО.
Среди пропагандистского слабоумия и острого когнитивного диссонанса, охватившего всю сферу NATOstan, единственным противоядием служат редкие голоса разума, которые, как оказалось, являются русскими, поэтому замолкают и/или отклоняются. Запад игнорирует их на свой страх и риск.
Патрушев идет Triple-X unplugged
Начнем с выступления президента Путина на Совете законодателей в Санкт-Петербурге по случаю Дня российского парламентаризма.
Путин продемонстрировал, как едва ли новое “геополитическое оружие”, опирающееся на “русофобию и неонацистов”, вкупе с усилиями “экономического удушения” не только не смогло задушить Россию, но и внедрило в коллективное бессознательное ощущение экзистенциального конфликта - “Второй Великой Отечественной войны”.
С зашкаливающей истерией по всему спектру сообщение для Империи, которая все еще отказывается слушать и даже не понимает значения “неделимости безопасности”, должно было быть неизбежным:
“Хотел бы еще раз подчеркнуть, что если кто-то намерен вмешиваться в происходящие события извне и создает неприемлемые для России угрозы стратегического характера, он должен знать, что наши ответные удары будут молниеносными. У нас есть все инструменты для этого. Такой, какой сейчас не может похвастаться никто. И мы не будем хвастаться. Мы воспользуемся ими, если потребуется. И я хочу, чтобы об этом знали все – мы приняли все решения по этому вопросу”.
Безостановочные провокации могут привести к тому, что г-н Кинжал, г-н Циркон и г-н Сармат будут вынуждены представить свои визитные карточки в избранных западных широтах, даже без официального приглашения.
Возможно, впервые с начала операции Z Путин провел различие между военными операциями на Донбассе и остальной частью Украины. Это напрямую связано с интеграцией Херсона, Запорожья и Харькова и подразумевает, что российские Вооруженные силы будут идти и идти, устанавливая суверенитет не только в Донецкой и Луганской Народных Республиках, но и над Херсоном, Запорожьем и далее по дороге от Азовского моря до Черного Моря, вплоть до установления полного контроля над Николаевом и Одессой.
Формула предельно ясна: “Россия не может допустить создания антироссийских территорий вокруг страны”.
Теперь перейдем к чрезвычайно подробному интервью секретаря Совета Безопасности Николая Патрушева "Российской газете", где Патрушев как бы отключил triple-X.
Ключевой вывод может быть здесь: “Крах американо-ориентированного мира - это реальность, в которой нужно жить и строить оптимальную линию поведения”. “Оптимальная линия поведения” России – к большому гневу универсалистского и одностороннего гегемона – включает в себя “суверенитет, культурную и духовную идентичность и историческую память”.
Патрушев показывает, как “трагические сценарии мировых кризисов, как в прошлые годы, так и сегодня, навязываются Вашингтоном в его стремлении укрепить свою гегемонию, сопротивляясь распаду однополярного мира”. США идет на все, чтобы “добиться того, чтобы другие центры многополярного мира даже не посмели поднять головы, а наша страна не только посмела, но и публично заявила, что не будет играть по навязанным правилам”.
Патрушев не мог не подчеркнуть, как War Inc. буквально совершает убийство на Украине: “Американский и европейский военно-промышленный комплекс ликует, потому что благодаря кризису на Украине у него нет передышки от порядка. Неудивительно, что в отличие от России, заинтересованной в скорейшем завершении специальной военной операции и минимизации потерь со всех сторон, Запад полон решимости оттянуть ее хотя бы до последнего украинца”.
И это отражает психику американских элит: “Вы говорите о стране, элита которой не способна ценить чужие жизни. Американцы привыкли ходить по выжженной земле. Со времен Второй мировой войны целые города были стерты с лица земли бомбардировками, в том числе ядерными. Они затопили вьетнамские джунгли ядом, разбомбили сербов радиоактивными боеприпасами, заживо сожгли иракцев белым фосфором, помогли террористам отравить сирийцев хлором (...) Как показывает история, НАТО также никогда не было оборонительным союзом, только наступательным”.
Ранее в интервью восхитительно названному The Great Game show на российском телевидении министр иностранных дел Сергей Лавров еще раз подробно рассказал, как американцы “больше не настаивают на соблюдении международного права, а на уважении к "основанному на правилах мировому порядку’. Эти ‘правила’ никак не расшифрованы. Говорят, что сейчас мало правил. Для нас их вообще не существует. Существует международное право. Мы уважаем его, как и Устав ООН. Ключевое положение, главный принцип - суверенное равенство государств. США грубо нарушает свои обязательства по Уставу ООН, когда продвигает свои ‘правила’”.
Лаврову пришлось еще раз подчеркнуть, что нынешнюю раскаленную ситуацию можно сравнить с кубинским ракетным кризисом: “В те годы существовал канал связи, которому доверяли оба лидера. Сейчас такого канала нет. Никто не пытается его создать ”.
Империя лжи в ее нынешнем состоянии не занимается дипломатией.
Темп игры на новой шахматной доске
В тонком намеке на работу Сергея Глазьева, как объяснил в нашем недавнем интервью министр по интеграции и макроэкономике Евразийского экономического союза Патрушев попал в самое сердце нынешней геоэкономической игры, когда Россия сейчас активно движется к золотому стандарту: “Эксперты работают над предложенным научным сообществом проектом создания двухконтурной денежно-финансовой системы. В частности, предлагается определить стоимость рубля, который должен быть обеспечен как золотом, так и группой товаров, являющихся валютными ценностями, чтобы привести курс рубля в соответствие с реальным паритетом покупательной способности”.
Это было неизбежно после откровенного хищения более 300 миллиардов долларов российских валютных резервов. Возможно, Москве потребовалось несколько дней, чтобы полностью удостовериться, что она столкнулась с Totalen Krieg. Следствием этого является то, что коллективный Запад потерял всякую власть влиять на российские решения. Темп игры на новой шахматной доске задает Россия.
Ранее на этой неделе на встрече с генеральным секретарем ООН Антониу Гутеррешем Путин зашел так далеко, что заявил, что он будет более чем готов к переговорам – только с несколькими условиями: украинский нейтралитет и статус автономии для Донбасса. Но теперь все знают, что уже слишком поздно. Для Вашингтона в режиме Totalen Krieg переговоры являются анафемой - и это было так после встречи России и Украины в Стамбуле в конце марта.
До сих пор в операции Z российские вооруженные силы использовали только 12% своих солдат, 10% своих истребителей, 7% своих танков, 5% своих ракет и 4% своей артиллерии. Циферблат боли настроен на существенное повышение - и с полным освобождением Мариуполя и разрешением так или иначе котла Донбасса нет ничего, что могло бы сделать комбо истерии / пропаганды / оружия, развернутое коллективным Западом, чтобы изменить факты на местах.
Это включает в себя отчаянные гамбиты, такие как тот, который раскрыл СВР - российская внешняя разведка, которая очень редко ошибается. СВР выяснила, что ось Империя лжи / War Inc. настаивает не только на фактическом польском вторжении для аннексии Западной Украины под лозунгом “исторического воссоединения”, но и на совместном румынско-украинском вторжении в Молдову / Приднестровье, причем румынские “миротворцы” уже скапливаются рядом с границей Молдовы.
Вашингтон, как утверждает СВР, уже более месяца замышляет польский гамбит. Он будет “руководить сзади” (помните Ливию?), “поощряя” “группу стран” оккупировать Западную Украину. Итак, раздел уже на картах. Если бы это когда-нибудь материализовалось, было бы интересно поспорить, в каких местах мистер Сармат будет склонен распространять свою визитную карточку.
Аналитик составяющий свое заключение по неполным данным подобен игроку ставящему на число рулетки.
Взгляды отдельных авторов не обязательно отражают мою точку зрения
Гиперссылка на оригинальный материал находится в заголовке каждой статьи
Взгляды отдельных авторов не обязательно отражают мою точку зрения
Гиперссылка на оригинальный материал находится в заголовке каждой статьи
66 лет
Карма: +14.72
Регистрация: 16.11.2008
Сообщений: 4,046
Читатели: 4
Регистрация: 16.11.2008
Сообщений: 4,046
Читатели: 4
Вести из Европы
Глава ЕС раскритиковала российский газовый "шантаж", настаивая на том, что блок готов ответить
"Наш ответ будет немедленным, единым и скоординированным. Мы позаботимся о том, чтобы решение "Газпрома" оказало наименьшее влияние на потребителей ЕС ", - заявила Урсула фон дер Ляйен
ECHO24.CZ
28 апреля 2022 года
редактор: REMIX NEWS

Президент Европейской комиссии Урсула фон дер Ляйен выступает перед СМИ с президентом Франции Эммануэлем Макроном в преддверии европейского саммита в Елисейском дворце в Париже в среду, 23 июня 2021 года. (AP Photo / Michel Euler)
Президент Европейской комиссии Урсула фон дер Ляйен заявила, что попытка шантажа России путем приостановки поставок газа в некоторые европейские страны не увенчается успехом, и заверила европейских потребителей, что блок подготовился к такой мере.
Глава нижней палаты российского парламента Вячеслав Володин высоко оценил принятое в среду решение "Газпрома" прекратить поставки газа в Польшу и Болгарию из-за отказа этих стран оплачивать поставки в рублях.
Тем не менее, глава Еврокомиссии нанесла ответный удар, настаивая на том, что этот шаг "не стал неожиданностью" для блока, и настаивая на том, что две пострадавшие страны теперь получают поставки газа от своих европейских соседей.
Мы позаботимся о том, чтобы решение "Газпрома" оказало наименьшее возможное влияние на потребителей ЕС.⁰
сейчас получают газ от своих соседей по ЕС.
@EU_Commission также активизирует свою работу с региональными группами государств-членов, которые могут обеспечить немедленную солидарность друг с другом. pic.twitter.com/6Pc7yGkzOQ
Фон дер Ляйен назвала российский шаг попыткой использовать газ для "шантажа" европейских стран и сообщила, что исполнительная власть ЕС уже связалась со всеми государствами-членами, чтобы решить вопрос обеспечения достаточных поставок для всех членов ЕС.
"Наш ответ будет немедленным, единым и скоординированным. Мы позаботимся о том, чтобы решение "Газпрома" оказало наименьшее возможное влияние на потребителей ЕС ", - написала фон дер Ляйен в своем твиттере.
Заявление "Газпрома" - очередная попытка России шантажировать нас газом.
Мы готовы к такому сценарию. Мы разрабатываем наш скоординированный ответ ЕС.
Европейцы могут верить, что мы едины и солидарны с пострадавшими государствами-членами.
По ее словам, у стран-членов есть чрезвычайные планы именно на эту ситуацию, которые они подготовили в связи с российским вторжением на Украину.
Российский список так называемых "недружественных стран", в который до начала марта входили только США и Чехия, теперь содержит все страны ЕС и два десятка других государств, которые возражали против вторжения страны на Украину.
"Газпром" полностью прекратил поставки газа в Польшу и Болгарию в среду утром. По данным агентства ТАСС, причиной стал отказ местных газовых компаний оплачивать поставки в рублях, однако и Польша, и Болгария назвали действия российской компании нарушением контракта.
“Это правильное решение. Представители Госдумы поддерживают его ", - заявил глава нижней палаты парламента России Вячеслав Володин. "Болгария и Польша могли бы воспользоваться предложением нашего президента и заплатить за газ в рублях. Необходимо действовать и в отношении других вражеских стран ", - добавил он.
7 марта правительство России обновило список стран, которые считаются недружественными России в связи с санкциями, введенными против России Западом из-за военного вторжения на Украину. Москва также объявила, что финансовые обязательства России будут оплачиваться только в рублях.
"Примите более короткий душ и проветрите свою одежду вместо того, чтобы стирать ее!" - говорит вице-президент ЕК гражданам
Франс Тиммерманс отвечал на вопрос о планах регулирования отопления в ЕС
МАНДИНЕР
29 апреля 2022 года
редактор: REMIX NEWS

Европейский комиссар по европейскому зеленому соглашению Франс Тиммерманс прибывает на еженедельное заседание колледжа Европейской комиссии в штаб-квартире ЕС в Брюсселе в среду, 30 марта 2022 года. Европейский союз предупреждает потребителей прекратить использовать свою одежду как одноразовые ткани и планирует меры по противодействию растущему использованию загрязняющей "быстрой моды". (Кензо Трибуйяр, фото у бассейна через AP)
Вице-президент Европейской комиссии предложил европейским гражданам поддержать эмбарго ЕС против России, меньше принимая душ и проветривая свою одежду вместо того, чтобы стирать ее.
Франс Тиммерманс, голландский вице-президент исполнительного органа блока, предложил странные замечания на заседании Комитета по окружающей среде Европейского парламента.
”Меньше тепла, катайтесь на велосипеде и проветривайте свою одежду вместо того, чтобы стирать ее", - сказал Тиммерманс комитету, ответственному за зеленые изменения. По словам голландского политика, населению необходимо предпринять такие действия, чтобы поддержать карательные меры, принимаемые против России после ее вторжения в Украину 24 февраля.
Эдина Тот, депутат Европарламента от Fidesz, задала следующий вопрос на заседании Комитета по окружающей среде Европейского парламента в четверг:
"С мая в школах и общественных зданиях Италии запрещено охлаждаться ниже 25 градусов, а зимой нагревать общественные здания выше 19 градусов. В начале сессии Тиммерманс попросил граждан отключить отопление в своих домах. Инициирует ли ЕС аналогичные меры на европейском уровне? И вы хотите прописать, сколько градусов они хотят нагревать здания? На практике, как они хотят это контролировать?”
В ответ Тиммерманс отверг идею о том, что он оказывает чрезмерное давление на европейские домохозяйства своими советами, настаивая на том, что вместо этого он просто говорит своим "согражданам, что они тоже могут сделать что-то, чтобы перевести меньше денег в карман Путина.
”Конечно, они также могут ничего не делать, но они также могут меньше нагреваться, ездить на велосипеде, а не на машине, принимать более короткие души и проветривать свою одежду вместо того, чтобы стирать ее", - добавил голландский политик.
Глава ЕС раскритиковала российский газовый "шантаж", настаивая на том, что блок готов ответить
"Наш ответ будет немедленным, единым и скоординированным. Мы позаботимся о том, чтобы решение "Газпрома" оказало наименьшее влияние на потребителей ЕС ", - заявила Урсула фон дер Ляйен
ECHO24.CZ
28 апреля 2022 года
редактор: REMIX NEWS
Президент Европейской комиссии Урсула фон дер Ляйен выступает перед СМИ с президентом Франции Эммануэлем Макроном в преддверии европейского саммита в Елисейском дворце в Париже в среду, 23 июня 2021 года. (AP Photo / Michel Euler)
Президент Европейской комиссии Урсула фон дер Ляйен заявила, что попытка шантажа России путем приостановки поставок газа в некоторые европейские страны не увенчается успехом, и заверила европейских потребителей, что блок подготовился к такой мере.
Глава нижней палаты российского парламента Вячеслав Володин высоко оценил принятое в среду решение "Газпрома" прекратить поставки газа в Польшу и Болгарию из-за отказа этих стран оплачивать поставки в рублях.
Тем не менее, глава Еврокомиссии нанесла ответный удар, настаивая на том, что этот шаг "не стал неожиданностью" для блока, и настаивая на том, что две пострадавшие страны теперь получают поставки газа от своих европейских соседей.
Мы позаботимся о том, чтобы решение "Газпрома" оказало наименьшее возможное влияние на потребителей ЕС.⁰
сейчас получают газ от своих соседей по ЕС.
@EU_Commission также активизирует свою работу с региональными группами государств-членов, которые могут обеспечить немедленную солидарность друг с другом. pic.twitter.com/6Pc7yGkzOQ
— Ursula von der Leyen (@vonderleyen) April 27, 2022
Фон дер Ляйен назвала российский шаг попыткой использовать газ для "шантажа" европейских стран и сообщила, что исполнительная власть ЕС уже связалась со всеми государствами-членами, чтобы решить вопрос обеспечения достаточных поставок для всех членов ЕС.
"Наш ответ будет немедленным, единым и скоординированным. Мы позаботимся о том, чтобы решение "Газпрома" оказало наименьшее возможное влияние на потребителей ЕС ", - написала фон дер Ляйен в своем твиттере.
Заявление "Газпрома" - очередная попытка России шантажировать нас газом.
Мы готовы к такому сценарию. Мы разрабатываем наш скоординированный ответ ЕС.
Европейцы могут верить, что мы едины и солидарны с пострадавшими государствами-членами.
— Ursula von der Leyen (@vonderleyen) April 27, 2022
По ее словам, у стран-членов есть чрезвычайные планы именно на эту ситуацию, которые они подготовили в связи с российским вторжением на Украину.
Российский список так называемых "недружественных стран", в который до начала марта входили только США и Чехия, теперь содержит все страны ЕС и два десятка других государств, которые возражали против вторжения страны на Украину.
"Газпром" полностью прекратил поставки газа в Польшу и Болгарию в среду утром. По данным агентства ТАСС, причиной стал отказ местных газовых компаний оплачивать поставки в рублях, однако и Польша, и Болгария назвали действия российской компании нарушением контракта.
“Это правильное решение. Представители Госдумы поддерживают его ", - заявил глава нижней палаты парламента России Вячеслав Володин. "Болгария и Польша могли бы воспользоваться предложением нашего президента и заплатить за газ в рублях. Необходимо действовать и в отношении других вражеских стран ", - добавил он.
7 марта правительство России обновило список стран, которые считаются недружественными России в связи с санкциями, введенными против России Западом из-за военного вторжения на Украину. Москва также объявила, что финансовые обязательства России будут оплачиваться только в рублях.
"Примите более короткий душ и проветрите свою одежду вместо того, чтобы стирать ее!" - говорит вице-президент ЕК гражданам
Франс Тиммерманс отвечал на вопрос о планах регулирования отопления в ЕС
МАНДИНЕР
29 апреля 2022 года
редактор: REMIX NEWS
Европейский комиссар по европейскому зеленому соглашению Франс Тиммерманс прибывает на еженедельное заседание колледжа Европейской комиссии в штаб-квартире ЕС в Брюсселе в среду, 30 марта 2022 года. Европейский союз предупреждает потребителей прекратить использовать свою одежду как одноразовые ткани и планирует меры по противодействию растущему использованию загрязняющей "быстрой моды". (Кензо Трибуйяр, фото у бассейна через AP)
Вице-президент Европейской комиссии предложил европейским гражданам поддержать эмбарго ЕС против России, меньше принимая душ и проветривая свою одежду вместо того, чтобы стирать ее.
Франс Тиммерманс, голландский вице-президент исполнительного органа блока, предложил странные замечания на заседании Комитета по окружающей среде Европейского парламента.
”Меньше тепла, катайтесь на велосипеде и проветривайте свою одежду вместо того, чтобы стирать ее", - сказал Тиммерманс комитету, ответственному за зеленые изменения. По словам голландского политика, населению необходимо предпринять такие действия, чтобы поддержать карательные меры, принимаемые против России после ее вторжения в Украину 24 февраля.
Эдина Тот, депутат Европарламента от Fidesz, задала следующий вопрос на заседании Комитета по окружающей среде Европейского парламента в четверг:
"С мая в школах и общественных зданиях Италии запрещено охлаждаться ниже 25 градусов, а зимой нагревать общественные здания выше 19 градусов. В начале сессии Тиммерманс попросил граждан отключить отопление в своих домах. Инициирует ли ЕС аналогичные меры на европейском уровне? И вы хотите прописать, сколько градусов они хотят нагревать здания? На практике, как они хотят это контролировать?”
В ответ Тиммерманс отверг идею о том, что он оказывает чрезмерное давление на европейские домохозяйства своими советами, настаивая на том, что вместо этого он просто говорит своим "согражданам, что они тоже могут сделать что-то, чтобы перевести меньше денег в карман Путина.
”Конечно, они также могут ничего не делать, но они также могут меньше нагреваться, ездить на велосипеде, а не на машине, принимать более короткие души и проветривать свою одежду вместо того, чтобы стирать ее", - добавил голландский политик.
Аналитик составяющий свое заключение по неполным данным подобен игроку ставящему на число рулетки.
Взгляды отдельных авторов не обязательно отражают мою точку зрения
Гиперссылка на оригинальный материал находится в заголовке каждой статьи
Взгляды отдельных авторов не обязательно отражают мою точку зрения
Гиперссылка на оригинальный материал находится в заголовке каждой статьи
Сейчас на ветке:
4,
Модераторов: 0,
Пользователей: 0,
Гостей: 1,
Ботов: 3